Quantum Computing
Alright, so now we've got this beautiful theory of quantum mechanics, and the possibly-even-more-beautiful theory of computational complexity. Clearly, with two theories this beautiful, you can't just let them stay single -- you have to set them up, see if they hit it off, etc.
And that brings us to the class BQP: Bounded-Error Quantum Polynomial-Time. We talked in Lecture 7 about BPP, or Bounded-Error Probabilistic Polynomial-Time. Informally, BPP is the class of computational problems that are efficiently solvable in the physical world if classical physics is true. Now we ask, what problems are efficiently solvable in the physical world if (as seems more likely) quantum physics is true?
To me it's sort of astounding that it took until the 1990's for anyone to really seriously ask this question, given that all the tools for asking it were in place by the 1960's or even earlier. It makes you wonder, what similarly obvious questions are there today that no one's asking?
So how do we define BQP? Well, there are four things we need to take care of.
1. Initialization. We say, we have a system consisting of n quantum bits (or qubits), and these are all initialized to some simple, easy-to-prepare state. For convenience, we usually take that to be a "computational basis state," though later in the course we'll consider relaxing that assumption. In particular, if the input string is x, then the initial state will have the form |x⟩|0...0⟩: that is, |x⟩ together with as many "ancilla" qubits as we want initialized to the all-0 state.
2. Transformations. At any time, the state of our computer will be a superposition over all 2p(n) p(n)-bit strings, where p is some polynomial in n:
But what operations can we use to transform one superposition state to another? Since this is quantum mechanics, the operations should be unitary transformations -- but which ones? Given any Boolean function f:{0,1}n→{0,1}, there's some unitary transformation that will instantly compute the function for us -- namely, the one that maps each input |x⟩|0⟩ to |x⟩|f(x)⟩!
But of course, for most functions f, we can't apply that transformation efficiently. Exactly by analogy to classical computing -- where we're only interested in those circuits that can be built up by composing a small number of AND, OR, and NOT gates -- here we're only interested in those unitary transformations that can be built up by composing a small number of quantum gates. By a "quantum gate," I just mean a unitary transformation that acts on a small number of qubits -- say 1, 2, or 3.
Alright, let's see some examples of quantum gates. One famous example is the Hadamard gate, which acts as follows on a single qubit:
Another example is the Toffoli gate, which acts as follows on three qubits:
Or in words, the Toffoli gate flips the third qubit if and only if the first two qubits are both 1. Note that the Toffoli gate actually makes sense for classical computers as well.
Now, it was shown by Shi that the Toffoli and Hadamard already constitute a universal set of quantum gates. This means, informally, that they're all you ever need for a quantum computer -- since if we wanted to, we could use them to approximate any other quantum gate arbitrarily closely. (Or technically, any gate whose unitary matrix has real numbers only, no complex numbers. But that turns out not to matter for computing purposes.) Furthermore, by a result called the Solovay-Kitaev Theorem, any universal set of gates can simulate any other universal set efficiently -- that is, with at most a polynomial increase in the number of gates. So as long as we're doing complexity theory, it really doesn't matter which universal gate set we choose.
(This is exactly analogous to how, in the classical world, we could build our circuits out of AND, OR, and NOT gates, out of AND and NOT gates only, or even out of NAND gates only.)
Now, you might ask: which quantum gate sets have this property of universality? Is it only very special ones? On the contrary, it turns out that in a certain precise sense, almost any set of 1- and 2-qubit gates (indeed, almost any single 2-qubit gate) will be universal. But there are certainly exceptions to the rule. For example, suppose you had only the Hadamard gate (defined above) together with the following "controlled-NOT" gate:
That seems like a natural universal set of quantum gates, but it isn't. The so-called Gottesman-Knill Theorem shows that any quantum circuit consisting entirely of Hadamard and controlled-NOT gates can be simulated efficiently by a classical computer.
Now, once we fix a universal set (any universal set) of quantum gates, we'll be interested in those circuits consisting of at most p(n) gates from our set, where p is a polynomial, and n is the number of bits of the problem instance we want to solve. We call these the polynomial-size quantum circuits.
3. Measurement. How do we read out the answer when the computation is all done? Simple: we measure some designated qubit, reject if we get outcome |0⟩, and accept if we get outcome |1⟩! (Recall that for simplicity, we're only interested here in decision problems -- that is, problems having a yes-or-no answer.)
We further stipulate that, if the answer to our problem was "yes," then the final measurement should accept with probability at least 2/3, whereas if the answer was "no," then it should accept with probability at most 1/3. This is exactly the same requirement as for BPP. And as with BPP, we can replace the 2/3 and 1/3 by any other numbers we want (for example, 1-2-500 and 2-500), by simply repeating the computation a suitable number of times and then outputting the majority answer.
Now, immediately there's a question: would we get a more powerful model of computation if we allowed not just one measurement, but many measurements throughout the computation!
It turns out that the answer is no -- the reason being that you can always simulate a measurement (other than the final measurement, the one that "counts") using a unitary quantum gate. You can say, instead of measuring qubit A, let's apply a controlled-NOT gate from qubit A into qubit B, and then ignore qubit B for the rest of the computation. Then it's as if some third party measured qubit A -- the two views are mathematically equivalent. (Is this a trivial technical point or a profound philosophical point? You be the judge...)
4. Uniformity. Before we can give the definition of BQP, there's one last technical issue we need to deal with. We talked about a "polynomial-size quantum circuit," but more correctly it's an infinite family of circuits, one for each input length n. Now, can the circuits in this family be chosen arbitrarily, completely independent of each other? If so, then we could use them to (for example) solve the halting problem, by just hardwiring into the nth circuit whether or not the nth Turing machine halts. If we want to rule that out, then we need to impose a requirement called uniformity. This means that there should exist a (classical) algorithm that, given n as input, outputs the nth quantum circuit in time polynomial in n.
Exercise. Show that letting a polynomial-time quantum algorithm output the nth circuit would lead to the same definition.
Alright, we're finally ready to put the pieces together and give a definition of BQP.
BQP is the class of languages L ⊆ {0,1}* for which there exists a uniform family of polynomial-size quantum circuits, {Cn}, such that for all x ∈ {0,1}n:
Uncomputing
So, what can we say about BQP?
Well, as a first question, let's say you have a BQP algorithm that calls another BQP algorithm as a subroutine. Could that be more powerful than BQP itself? Or in other words, could BQPBQP (that is, BQP with a BQP oracle) be more powerful than BQP?
Right! Incidentally, this is related to something I was talking to Dave Bacon about. Why do physicists have so much trouble understanding the class NP? I suspect it's because NP, with its "magical" existential quantifier layered on top of a polynomial-time computation, is not the sort of thing they'd ever come up with. The classes that physicists would come up with -- the physicist complexity classes -- are hard to delineate precisely, but one property I think they'd definitely have is "closure under the obvious things," like one algorithm from the class calling another algorithm from the same class as a subroutine.
I claim that BQP is an acceptable "physicist complexity class" -- and in particular, that BQPBQP = BQP. What's the problem in showing this?
Right, garbage! Recall that when a quantum algorithm is finished, you measure just a single qubit to obtain the yes-or-no answer. So, what to do with all the other qubits? Normally you'd just throw it away. But now let's say you've got a superposition over different runs of an algorithm, and you want to bring the results of those runs together and interfere them. In that case, the garbage might prevent the different branches from interfering! So what do you do to fix this?
The solution, proposed by Bennett in the 1980's, is to uncompute. Here's how it works:
As you'd see if you visited my apartment, this is not the solution I generally adopt. But if you're a quantum computer, cleaning up the messes you make is a good idea.
Relation to Classical Complexity Classes
Alright, so how does BQP relate to the complexity classes we've already seen?
First, I claim that BPP ⊆ BQP: in other words, anything you can do with a classical probabilistic computer, you can also do with a quantum computer. Why?
Right: because any time you were gonna flip a coin, you just apply a Hadamard gate instead. In textbooks, this usually takes about a page to prove. We just proved it.
Can we get any upper bound on BQP in terms of classical complexity classes?
Sure we can! First of all, it's pretty easy to see that BQP ⊆ EXP: anything you can compute in quantum polynomial time you can also compute in classical exponential time. Or to put it differently, quantum computers can provide at most an exponential advantage over classical computers. Why is that?
Right: because if you allow exponential slowdown, then a classical computer can just simulate the whole evolution of the state vector!
As it turns out, we can do a lot better than that. Recall that PP is the class of problems like the following:
In other words, a PP problem involves summing up exponentially many terms, and then deciding whether the sum is greater or less than some threshold. Certainly PP is contained in PSPACE is contained in EXP.
In their original paper on quantum complexity, Bernstein and Vazirani showed that BQP ⊆ PSPACE. Shortly afterward, Adleman, DeMarrais, and Huang improved their result to show that BQP ⊆ PP. (This was also the first complexity result I proved. Had I known that Adleman et al. had proved it a year before, I might never have gotten started in this business! Occasionally it's better to have a small academic light-cone.)
So, why is BQP contained in PP? From a computer science perspective, the proof is maybe half a page. From a physics perspective, the proof is three words:
Look, let's say you want to calculate the probability that a quantum computer accepts. The obvious way to do it is to multiply a bunch of 2n-by-2n unitary matrices, then take the sum of the squares of the absolute values of the amplitudes corresponding to accepting basis states (that is, basis states for which the output qubit is |1⟩). What Feynman noticed in the 1940's is that there's a better way -- a way that's vastly more efficient in terms of memory (or paper), though still exponential in terms of time.
The better way is to loop over accepting basis states, and for each one, loop over all computational paths that might contribute amplitude to that basis state. So for example, let αx be the final amplitude of basis state |x⟩. Then we can write
where each αx,i corresponds to a single leaf in an exponentially-large "possibility tree," and is therefore computable in classical polynomial time. Typically, the αx,i's will be complex numbers with wildly-differing phases, which will interfere destructively and cancel each other out; then αx will be the tiny residue left over. The reason quantum computing seems more powerful than classical computing is precisely that it seems hard to estimate that tiny residue using random sampling. Random sampling would work fine for (say) a typical US election, but estimating αx is more like the 2000 election.
Now, let S be the set of all accepting basis states. Then we can write the probability that our quantum computer accepts as
where * denotes complex conjugate. But this is just a sum of exponentially many terms, each of which is computable in P. We can therefore decide in PP whether paccept≤1/3 or paccept≥2/3.
From my perspective, Richard Feynman won the Nobel Prize in physics essentially for showing BQP is contained in PP.
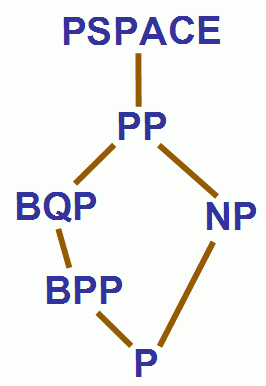
Currently-known inclusions.
Of course, the question that really gets people hot under the collar is whether BPP ≠ BQP: that is, whether quantum computing is more powerful than classical. Today we have evidence that this is indeed the case, most notably Shor's algorithm for factoring and discrete log. I'll assume you've seen this algorithm, since it was one of the major scientific achievements of the late 20th century, and is why we're here in Waterloo talking about these things in the first place. If you haven't seen it, there are about 500,000 expositions on the web.
It's worth stressing that, even before Shor's algorithm, computer scientists had amassed formal evidence that quantum computers were more powerful than classical ones. Indeed, this evidence is what paved the way for Shor's algorithm.
One major piece of evidence was Simon's algorithm, which many of you have also seen. Suppose we have a function f:{0,1}n→ {0,1}n, which we can access only as a "black box" (that is, by feeding it inputs and examining the outputs). We're promised that there exists a "secret XOR-mask" s∈{0,1}n, such that for all distinct (x,y) pairs, f(x)=f(y) if and only if x⊕y=s. (Here ⊕ denotes bitwise XOR.) Our goal is to learn the identity of s. The question is, how many times do we need to query f to do that with high probability?
Classically, it's easy to see that ~2n/2 queries are necessary and sufficient. As soon as we find a collision (a pair x≠y such that f(x)=f(y)), we know that s=x⊕y, and hence we're done. But until we find a collision, the function looks essentially random. In particular, if we query the function on T inputs, then the probability of finding a collision is at most ~T2/2n by the union bound. Hence we need T≈2n/2 queries to find s with high probability.
On the other hand, Simon gave a quantum algorithm that finds s using only ~n queries. The basic idea is to query f in superposition, and thereby prepare quantum states of the form
for random (x,y) pairs such that x⊕y=s. We then use the so-called quantum Fourier transform to extract information about s from these states. This use of the Fourier transform to extract "hidden periodicity information" provided a direct inspiration for Shor's algorithm, which does something similar over the abelian group ZN instead of . (In a by-now famous story, Simon's paper got rejected the first time he submitted it to a conference -- apparently Shor was one of the few people who got the point of it.)
Again, I won't go through the details of Simon's algorithm; see here if you want them.
So, the bottom line is that we get a problem -- Simon's problem -- that quantum computers can provably solve exponentially faster than classical computers. Admittedly, this problem is rather contrived, relying as it does on a mythical "black box" for computing a function f with a certain global symmetry. Because of its black-box formulation, Simon's problem certainly doesn't prove that BPP ≠ BQP. What it does prove that there exists an oracle relative to which BPP ≠ BQP. This is what I meant by formal evidence that quantum computers are more powerful than classical ones.
As it happens, Simon's problem was not the first to yield an oracle separation between BPP and BQP. Just as Shor was begotten of Simon, so Simon was begotten of Bernstein-Vazirani. In the long-ago dark ages of 1993, Bernstein and Vazirani devised a black-box problem called Recursive Fourier Sampling. They were able to prove that any classical algorithm needs at least ~nlog n queries to solve this problem, whereas there exists a quantum algorithm to solve it using only n queries.
Unfortunately, even to define the Recursive Fourier Sampling problem would take a longer digression than I feel is prudent. (If you think Simon's problem was artificial, you ain't seen nuthin'!) But the basic idea is this. Suppose we have black-box access to a Boolean function f:{0,1}n→{0,1}. We're promised that there exists a "secret string" s∈{0,1}n, such that f(x)=s•x for all x (where • denotes the inner product mod 2). Our goal is to learn s, using as few queries to f as possible.
In other words: we know that f(x) is just the XOR of some subset of input bits; our goal is to find out which subset.
Classically, it's obvious that n queries to f are necessary and sufficient: we're trying to learn n bits, and each query can only reveal one! But quantumly, Bernstein and Vazirani observed that you can learn s with just a single query. To do so, you simply prepare the state
then apply Hadamard gates to all n qubits. The result is easily checked to be |s⟩.
What Bernstein and Vazirani did was to start from the problem described above -- called Fourier sampling -- and then compose it recursively. In other words, they created a Fourier sampling problem where to learn one of the bits f(x), you need to solve another Fourier sampling problem, and to learn one of the bits in that problem you need to solve a third problem, and so on. They then showed that, if the recursion is d levels deep, then any randomized algorithm to solve this Recursive Fourier Sampling problem must make at least ~nd queries. By contrast, there exists a quantum algorithm that solves the problem using only 2d queries.
Compute {
 Compute {
Compute
Uncompute
}
Uncompute {
Compute
Uncompute
}
Compute {
Compute
Uncompute
}
Uncompute {
Compute
Uncompute
}
}
Uncompute {
Compute {
Compute
Uncompute
}
Uncompute {
Compute
Uncompute
}
}
Indeed, one of my results shows that this sort of recursive uncomputation is unavoidable feature of any quantum algorithm for Recursive Fourier Sampling.
So, once we have this gap of nd versus 2d, setting d=log n gives us nlog n queries on a classical computer versus 2log n=n queries on a quantum computer. Admittedly, this separation is not exponential versus polynomial -- it's only "quasipolynomial" versus polynomial. But that's still enough to prove an oracle separation between BPP and BQP.
You might wonder: now that we have Simon's and Shor's algorithms -- which do achieve an exponential separation between quantum and classical -- why muck around with this recursive archeological relic? Well, I'll tell you why. One of the biggest open problems in quantum computing concerns the relationship between BQP and the polynomial hierarchy PH (defined in Lecture 6). Specifically, is BQP contained in PH? Sure, it seems unlikely -- but as Bernstein and Vazirani asked back in '93, can we actually find an oracle relative to which BQP ⊄ PH? Alas, fourteen years and maybe a half-dozen disillusioned grad students later, the answer is still no. Yet many of us still believe a separation should be possible -- and the significance of Recursive Fourier Sampling is that it's practically the only candidate problem we have for such a separation.
Quantum Computing and NP-complete Problems
From reading newspapers, magazines, Slashdot, and so on, one would think a quantum computer could "solve NP-complete problems in a heartbeat" by "trying every possible solution in parallel," and then instantly picking the correct one.
Well, that's a crock. Indeed, arguably it's the central crock about quantum computing.
Obviously, we can't yet prove that quantum computers can't solve NP-complete problems efficiently -- in other words, that NP ⊄ BQP -- since we can't even prove that P ≠ NP! Nor do we have any idea how to prove that if P ≠ NP then NP ⊄ BQP.
What we do have is the early result of Bennett, Bernstein, Brassard, and Vazirani, that there exists an oracle relative to which NP ⊄ BQP. More concretely, suppose you're searching a space of 2n possible solutions for a single valid one, and suppose that all you can do, given a candidate solution, is feed it to a 'black box' that tells you whether that solution is correct or not. Then how many times do you need to query the black box to find the valid solution? Classically, it's clear that you need to query it ~2n times in the worst case (or ~2n/2 times on average). On the other hand, Grover famously gave a quantum search algorithm that queries the black box only ~2n/2 times. But even before Grover's algorithm was discovered, Bennett et al. had proved that it was optimal! In other words, any quantum algorithm to find a needle in a size-2n haystack needs at least ~2n/2 steps. So the bottom line is that, for "generic" or "unstructured" search problems, quantum computers can give some speedup over classical computers -- specifically, a quadratic speedup -- but nothing like the exponential speedup of Shor's factoring algorithm.
You might wonder: why should the speedup be quadratic, rather than cubic or something else? Let me try to answer that question without getting into the specifics either of Grover's algorithm, or of the Bennett et al. optimality proof. Basically, the reason we get a quadratic speedup is that quantum mechanics is based on the L2 norm rather than the L1 norm. Classically, if there are N solutions, only one of which is right, then after one query we have a 1/N probability of having guessed the right solution, after two queries we have a 2/N probability, after three queries a 3/N probability, and so on. Thus we need ~N queries to have a non-negligible (i.e. close to 1) probability of having guessed the right solution. But quantumly, we get to apply linear transformations to vectors of amplitudes, which are the square roots of probabilities. So the way to think about it is this: after one query we have a 1/√N amplitude of having guessed the right solution, after two queries we have a 2/√N amplitude, after three queries a 3/√N amplitude, and so on. So after T queries, the amplitude of having guessed a right solution is T/√N, and the probability is |T/√N|2 = T2/N. Hence the probability will be close to 1 after only T ≈ √N queries.
Alright, those of you who read my blog must be tired of polemics about the limitations of quantum computers on unstructured search problems. So I'm going to take the liberty of ending this section now.
Quantum Computing and Many-Worlds
Since this course is Quantum Computing Since Democritus, I guess I should end today's lecture with a deep philosophical question. Alright, so how about this one: if we managed to build a nontrivial quantum computer, would that demonstrate the existence of parallel universes?
David Deutsch, one of the founders of quantum computing in the 1980's, certainly thinks that it would. (Though to be fair, Deutsch thinks the impact would "merely" be psychological -- since for him, quantum mechanics has already proved the existence of parallel universes!) Deutsch is fond of asking questions like the following: if Shor's algorithm succeeds in factoring a 3000-digit integer, then where was the number factored? Where did the computational resources needed to factor the number come from, if not from some sort of 'multiverse' exponentially bigger than the universe we see? To my mind, Deutsch seems to be tacitly assuming here that factoring is not in BPP -- but no matter; for purposes of argument we can certainly grant him that assumption.
It should surprise no one that Deutsch's views about this are far from universally accepted. Many who agree about the possibility of building quantum computers, and the formalism needed to describe them, nevertheless disagree that the formalism is best interpreted in terms of "parallel universes." To Deutsch, these people are simply intellectual wusses -- like the Churchmen who agreed that Copernican system was practically useful, so long as one remembers that obviously the Earth doesn't really go around the sun.
So, how do the intellectual wusses respond to the charges? For one thing, they point out that viewing a quantum computer in terms of "parallel universes" raises serious difficulties of its own. In particular, there's what those condemned to worry about such things call the "preferred basis problem." The problem is basically this: how do we define a "split" between one parallel universe and another? There are infinitely many ways you could imagine slicing up a quantum state, and it's not clear why one is better than another!
One can push the argument further. The key thing that quantum computers rely on for speedups -- indeed, the thing that makes quantum mechanics different from classical probability theory in the first place -- is interference between positive and negative amplitudes. But to whatever extent different "branches" of the multiverse can usefully interfere for quantum computing, to that extent they don't seem like separate branches at all! I mean, the whole point of interference is to mix branches together so that they lose their individual identities. If they retain their identities, then for exactly that reason we don't see interference.
Of course a many-worlder could respond that, in order to lose their separate identities by interfering with each others, the branches had to be there in the first place! And the argument could go on (indeed, has gone on) for quite a while.
Rather than take sides in this fraught, fascinating, but perhaps ultimately-meaningless debate, I'd like to end with one observation that's not up for dispute. What Bennett et al.'s lower bound tells us is that, if quantum computing supports the existence of parallel universes, then it certainly doesn't do so in the way most people think! As we've seen, a quantum computer is not a device that could "try every possible solution in parallel" and then instantly pick the correct one. If we insist on seeing things in terms of parallel universes, then those universes all have to "collaborate" -- more than that, have to meld into each other -- to create an interference pattern that will lead to the correct answer being observed with high probability.
[Discussion of this lecture on blog]