(Thanks to Gus Gutoski for help preparing these notes.)
This lecture begins with Scott bitching out the class for not attempting the puzzle questions. Bunch of lazy punks.
Answers to Puzzles from Lecture 7
Puzzle 1. We are given a biased coin that comes up heads with probability p. Using this coin, construct an unbiased coin.
Solution. The solution is the "von Neumann trick": flip the biased coin twice, interpreting HT as heads and TH as tails. If the flips come up HH or TT then try again. Under this scheme, "heads" and "tails" are equiprobable, each occurring with probability p(1-p) in any given trial. Conditioned on either HT or TH occurring, it follows that the simulated coin is unbiased.
Puzzle 2. n people sit in a circle. Each person wears either a red hat or a blue hat, chosen independently and uniformly at random. Each person can see the hats of all the other people, but not his/her own hat. Based only upon what they see, each person votes on whether or not the total number of red hats is odd. Is there a scheme by which the outcome of the vote is correct with probability greater than 1/2?
Solution. Each person decides his/her vote as follows: if the number of visible blue hats is larger than the number of visible red hats then vote according to the parity of the number of visible red hats. Otherwise, vote the opposite of the parity of the number of visible red hats. If the number of red hats differs from the number of blue hats by at least 2 then this scheme succeeds with certainty. Otherwise the scheme might fail. However, the probability that the number of red hats differs from the number of blue hats by less than 2 is small -- O(1/√n).
Crypto
Cryptography has been a major force in human history for more than 3,000 years. Numerous wars have been won or lost by the sophistication or stupidity of cryptosystems. If you think I'm exaggerating, read The Codebreakers by David Kahn, and keep in mind that it was written before people knew about the biggest cryptographic story of all, Turing's victory in the Second World War.
And yet, even though cryptography has influenced human affairs for millennia, developments over the last thirty years have completely -- yes, completely -- changed our understanding of it. If you plotted when the basic mathematical discoveries in cryptography were made, you'd see a few in antiquity, maybe a few from the Middle Ages till the 1800's, one in the 1920's (the one-time pad), a few more around World War II, and then, after the birth of computational complexity theory in the 1970's, boom boom boom boom boom boom boom...
Our journey through the history of cryptography begins with the famous and pathetic "Caesar cipher" used by the Roman Empire. Here the plaintext message is converted into a ciphertext by simply adding 3 to each letter, wrapping around to A after you reach Z. Thus D becomes G, Y becomes B, and DEMOCRITUS becomes GHPRFULWXV. More complex variants of the Caesar cipher have appeared, but given enough ciphertext they're all easy to crack, by using (for example) a frequency analysis of the letters appearing in the ciphertext. Not that that's stopped people from using these things! Indeed, as recently as last April, the head of the Sicilian mafia was finally caught after forty years because he used the Caesar cipher -- the original one -- to send messages to his subordinates!
It wasn't until the 1920's that an information-theoretically secure cryptosystem was devised: the one-time pad. The idea is simple: the plaintext message is represented by a binary string p, which is exclusive-OR'ed with a random binary key k of the same length. That is, the ciphertext c is equal to p + k, where + denotes bitwise addition mod 2.
The recipient (who knows k) can decrypt the ciphertext with another XOR operation:
To an eavesdropper who doesn't know k, the ciphertext is just a string of random bits -- since XOR'ing any string of bits with a random string just produces another random string. (To drive home just how random the ciphertext is, Scott makes up an example in class of a plaintext and key, which turn out to encrypt to the all-1 string -- very random-looking indeed!)
The problem with the one-time pad, of course, is that the sender and recipient have to share a key that's as long as the message itself. Furthermore, if the same key is ever used to encrypt two or more messages, then the cryptosystem is no longer information-theoretically secure. (Hence the name "one-time pad.") To see why, suppose two plaintexts p1 and p2 are both encrypted via the same key k to ciphertexts c1 and c2 respectively. Then we have
and hence an eavesdropper can obtain the string p1 + p2. By itself, this might or might not be useful, but it at least constitutes some information that an eavesdropper could learn about the plaintexts. But this is just a mathematical curiosity, right? Well, in the 1950's the Soviets got sloppy and reused some of their one-time pads. As a result, the NSA, through its VENONA project, was able to recover some (though not all) of the plaintext encrypted in this way. This seems to be how Julius and Ethel Rosenberg were caught.
In the 1940's, Claude Shannon proved that information-theoretically secure cryptography requires the sender and recipient to share a key at least as long as the message they want to communicate. Like pretty much all of Shannon's results, this one is trivial in retrospect. (It's good to be in on the ground floor!) Here's his proof: given the ciphertext and the key, the plaintext had better be uniquely recoverable. In other words, for any fixed key, the function that maps plaintexts to ciphertexts had better be an injective function. But this immediately implies that, for a given ciphertext c, the number of plaintexts that could possibly have produced c is at most the number of keys. In other words, if there are fewer possible keys than plaintexts, then an eavesdropper will be able to rule out some of the plaintexts -- the ones that wouldn't encrypt to c for any value of the key. Therefore our cryptosystem won't be perfectly secure. It follows that, if we want perfect security, then we need at least as many keys as plaintexts -- or equivalently, the key needs to have at least as many bits as the plaintext.
I mentioned before that sharing huge keys is usually impractical -- not even the KGB managed to do it perfectly! So we want a cryptosystem that lets us get away with smaller keys. Of course, Shannon's result implies that such a cryptosystem can't be information-theoretically secure. But what if we relax our requirements? In particular, what if we assume that the eavesdropper is restricted to running in polynomial time? This question leads naturally to our next topic...
Pseudorandom Generators
As I mentioned in the last lecture, a pseudorandom generator (PRG) is basically a function that takes as input a short, truly random string, and produces as output a long, seemingly random string. More formally, a pseudorandom generator is a function f with the following properties:
is negligibly small -- by which I mean, it decreases faster than 1/q(n) for any polynomial q. (Of course, decreasing at an exponential rate is even better.) Or in English, no polynomial-time adversary can distinguish the output of f from a truly random string with any non-negligible bias.
Now, you might wonder: how "stretchy" a PRG are we looking for? Do we want to stretch an n-bit seed to 2n bits? To n2 bits? n100 bits? The answer turns out to be irrelevant!
Why? Because even if we only had a PRG f that stretched n bits to n+1 bits, we could keep applying f recursively to its own output, and thereby stretch n bits to p(n) bits for any polynomial p. Furthermore, if the output of this recursive process were efficiently distinguishable from a random p(n)-bit string, then the output of f itself would have been efficiently distinguishable from a random (n+1)-bit string -- contrary to assumption! Of course, there's something that needs to be proved here, but the something that needs to be proved can be proved, and I'll leave it at that.
Now, I claim that if pseudorandom generators exist, then it's possible to build a computationally-secure cryptosystem using only short encryption keys. Does anyone see why?
Right: first use the PRG to stretch a short encryption key to a long one -- as long as the plaintext message itself. Then pretend that the long key is truly random, and use it exactly as you'd use a one-time pad!
Why is this scheme secure? As always in modern cryptography, what we do is to argue by reduction. Suppose that, given only the ciphertext message, an eavesdropper could learn something about the plaintext in polynomial time. We saw before that, if the encryption key were truly random (that is, were a one-time pad), then this would be impossible. It follows, then, that the eavesdropper would in effect be distinguishing the pseudorandom key from a random one. But this contradicts our assumption that no polynomial-time algorithm can distinguish the two!
Admittedly, this has all been pretty abstract and conceptual. Sure, we could do wonderful things if we had a PRG -- but is there any reason to suppose PRG's actually exist?
A first, trivial observation is that PRG's can only exist if P≠NP. Why?
Right: because if P=NP, then given a supposedly random string y, we can decide in polynomial time whether there's a short seed x such that f(x)=y. If y is random, then such a seed almost certainly won't exist -- so if it does exist, we can be almost certain that y isn't random. We can therefore distinguish the output of f from true randomness.
Alright, but suppose we do assume P≠NP. What are some concrete examples of functions that are believed to be pseudorandom generators?
One example is what's called the Blum-Blum-Shub generator. Here's how it works: pick a large composite number N. Then the seed, x, will be a random element of ZN. Given this seed, first compute x2 mod N, (x2)2 mod N, ((x2)2)2 mod N, and so on. Then concatenate the least-significant bits in the binary representations of these numbers, and output that as your pseudorandom string f(x).
Blum et al. were able to show that, if we had a polynomial-time algorithm to distinguish f(x) from a random string, then (modulo some technicalities) we could use that algorithm to factor N in polynomial time. Or equivalently, if factoring is hard, then Blum-Blum-Shub is a PRG. This is yet another example where we "prove" something is hard by showing that, if it were easy, then something else that we think is hard would also be easy.
Alas, we don't think factoring is hard -- at least, not in a world with quantum computers! So can we base the security of PRG's on a more quantum-safe assumption? Yes, we can. There are many, many ways to build a candidate PRG, and we have no reason to think that quantum computers will be able to break all of them. Indeed, you could even base a candidate PRG on the apparent unpredictability of (say) the "Rule 110" cellular automaton, as advocated by Stephen Wolfram in his groundbreaking, revolutionary, paradigm-smashing book.
Of course, our dream would be to base a PRG's security on the weakest possible assumption: P≠NP itself! But when people try to do that, they run into two interesting problems.
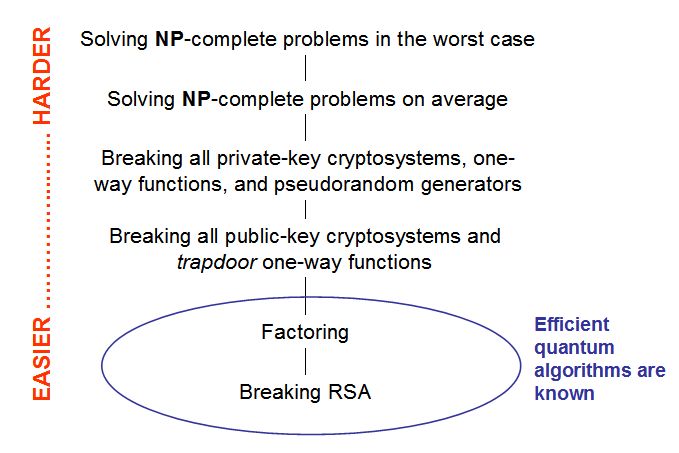
The first problem is that P versus NP deals only with the worst case. Imagine if you were a general or a bank president, and someone tried to sell you an encryption system with the sales pitch that there exists a message that's hard to decode. You see what the difficulty is: for both encryption systems and PRG's, we need NP problems that are hard on average, not just in the worst case. (Technically, we need problems that are hard on average with respect to some efficiently samplable distribution over the inputs -- not necessarily the uniform distribution.) But no one has been able to prove that such problems exist, even if we assume P≠NP.
That's not to say, though, that we know nothing about average-case hardness. As an example, consider the Shortest Vector Problem (SVP). Here we're given a lattice L in Rn, consisting of all integer linear combinations of some given vectors v1,...,vn in Rn. Then the problem is to approximate the length of the shortest nonzero vector in L to within some multiplicative factor k.
SVP is one of the few problems for which we can prove a worst-case / average-case equivalence (that is, the average case is every bit as hard as the worst case), at least when the approximation ratio k is big enough. Based on that equivalence, Ajtai, Dwork, Regev, and others have constructed cryptosystems and pseudorandom generators whose security rests on the worst-case hardness of SVP. Unfortunately, the same properties that let us prove worst-case / average-case equivalence also make it unlikely that SVP is NP-complete for the relevant values of k! It seems more likely that SVP is intermediate between P and NP-complete, just like we think factoring is.
Alright, so suppose we just assume NP-complete problems are hard on average. Even then, there's a further difficulty in using NP-complete problems to build a PRG. This is that breaking PRG's just doesn't seem to have the right "shape" to be NP-complete. What do I mean by that? Well, think about how we prove a problem B is NP-complete: we take some problem A that's already known to be NP-complete, and we give a polynomial-time reduction that maps yes-instances of A to yes-instances of B, and no-instances of A to no-instances of B. In the case of breaking a PRG, presumably the yes-instances would be pseudorandom strings and the no-instances would be truly random strings (or maybe vice versa).
Do you see the problem here? If not, let me spell it out for you: how do we describe a "truly random string" for the purpose of mapping to it in the reduction? The whole point of a string being random is that we can't describe it by anything shorter than itself! Admittedly, this argument is full of loopholes, one of which is that the reduction might be randomized. Nevertheless, it is possible to conclude something from the argument: that if breaking PRG's is NP-complete, then the proof will have to be very different from the sort of NP-completeness proofs that we're used to.
One-Way Functions
One-way functions are the cousins of pseudorandom generators. Intuitively, a one-way function (OWF) is just a function that's easy to compute but hard to invert. More formally, a function f from n bits to p(n) bits is a one way function if
is negligibly small -- that is, smaller than 1/q(n) for any polynomial q.
The event f(A(f(x))) = f(x) appears in the definition instead of just A(f(x)) = x in order to account for the fact that f might have multiple inverses. With this definition, we consider algorithms A that find anything in the preimage of f(x), not just x itself.
I claim that the existence of PRG's implies the existence of OWF's. Can anyone tell me why? Anyone?
Right: because a PRG is an OWF!
Alright then, can anyone prove that the existence of OWF's implies the existence of PRG's?
Yeah, this one's a little harder! The main reason is that the output of an OWF f doesn't have to appear random in order for f to be hard to invert. And indeed, it took more than a decade of work -- culminating in a behemoth 1997 paper of H�stad, Impagliazzo, Levin, and Luby -- to figure out how to construct a pseudorandom generator from any one-way function. Because of H�stad et al.'s result, we now know that OWF's exist if and only if PRG's do. The proof, as you'd expect, is pretty complicated, and the reduction is not exactly practical: the blowup is by about n40! This is the sort of thing that gives polynomial-time a bad name -- but it's the exception, not the rule! If we assume that the one-way function is a permutation, then the proof becomes much easier (it was already shown by Yao in 1982) and the reduction becomes much faster. But of course that yields a less general result.
So far we've restricted ourselves to private-key cryptosystems, which take for granted that the sender and receiver share a secret key. But how would you share a secret key with (say) Amazon.com before sending them your credit card number? Would you email them the key? Oops -- if you did that, then you'd better encrypt your email using another secret key, and so on ad infinitum! The solution, of course, is to meet with an Amazon employee in an abandoned garage at midnight.
No, wait ... I meant that the solution is public-key cryptography.
Public-Key Cryptography
It's amazing, if you think about it, that so basic an idea had to wait until the 1970's to be discovered. Physicists were tidying up the Standard Model while cryptographers were still at the Copernicus stage!
So, how did public-key cryptography finally come to be? The first inventors -- or rather discoverers -- were Ellis, Cocks, and Williamson, working for the GCHQ (the British NSA) in the early 70's. Of course they couldn't publish their work, so today they don't get much credit! Let that be a lesson to you.
The first public public-key cryptosystem was that of Diffie and Hellman, in 1976. A couple years later, Rivest, Shamir, and Adleman discovered the famous RSA system that bears their initials. Do any of you know how RSA was first revealed to the world? Right: as a puzzle in Martin Gardner's Mathematical Games column for Scientific American!
RSA had several advantages over Diffie-Hellman: for example, it only required one party to generate a public key instead of both, and it let users authenticate themselves in addition to communicating in private. But if you read Diffie and Hellman's paper, pretty much all the main ideas are there.
Anyway, the core of any public-key cryptosystem is what's called a trapdoor one-way function. This is a function that's
The first two requirements are just the same as for ordinary OWF's. The third requirement -- that the OWF should have a "trapdoor" that makes the inversion problem easy -- is the new one. For comparison, notice that the existence of ordinary one-way functions implies the existence of secure private-key cryptosystems, whereas the existence of trapdoor one-way functions implies the existence of secure public-key cryptosystems.
So, what's an actual example of a public-key cryptosystem? Well, most of you have seen RSA at some point in your mathematical lives, so I'll go through it quickly.
Let's say you want to send your credit card number to Amazon.com. What happens? First Amazon randomly selects two large prime numbers p and q (which can be done in polynomial time), subject to the technical constraint that p-1 and q-1 should not be divisible by 3. (We'll see the reason for that later.) Then Amazon computes the product N = pq and publishes it for all the world to see, while keeping p and q themselves a closely-guarded secret.
Now, assume without loss of generality your credit card number is encoded as a positive integer x, smaller but not too much smaller than N. Then what do you do? Simple: you compute x3 mod N and send it over to Amazon! If a credit card thief intercepted your message en route, then she would have to recover x given only x3 mod N. But computing cube roots modulo a composite number is believed to be an extremely hard problem, at least for classical computers! If p and q are both reasonably large (say 10,000 digits each), then our hope would be that any classical eavesdropper would need millions of years to recover x.
This leaves an obvious question: how does Amazon itself recover x? Duh -- by using its knowledge of p and q! We know from our friend Mr. Euler, way back in 1761, that the sequence
repeats with period (p-1)(q-1). So provided Amazon can find an integer k such that
it'll then have
Now, we know that such a k exists, by the assumption that p-1 and q-1 are not divisible by 3. Furthermore, Amazon can find such a k in polynomial time, using Euclid's algorithm (from way way back, around 300BC). Finally, given x3 mod N, Amazon can compute (x3)k in polynomial time by using a simple repeated squaring trick. So that's RSA.
(Note: to make everything as concrete and visceral as possible, I assumed that x always gets raised to the third power. The resulting cryptosystem is by no means a toy: as far as anyone knows, it's secure! In practice, though, people can and do raise x to arbitrary powers. As another remark, squaring x instead of cubing it would open a whole new can of worms, since any nonzero number that has a square root mod N has more than one of them.)
Of course, if the credit card thief could factor N into pq, then she could run the exact same decoding algorithm that Amazon runs, and thereby recover the message x. So the whole scheme relies crucially on the assumption that factoring is hard! This immediately implies that RSA could be broken by a credit card thief with a quantum computer. Classically, however, the best known factoring algorithm is the Number Field Sieve, which takes about steps.
As a side note, no one has yet proved that breaking RSA requires factoring: it's possible that there's a more direct way to recover the message x, one that doesn't entail learning p and q. On the other hand, in 1979 Rabin discovered a variant of RSA for which recovering the plaintext is provably as hard as factoring.
Alright, but all this talk of cryptosystems based on factoring and modular arithmetic is so 1993! Today we realize that as soon as we build a quantum computer, Shor's algorithm will break the whole lot of these things. Of course, this point hasn't been lost on complexity theorists, many of whom have since set to work looking for trapdoor OWF's that still seem safe against quantum computers. Currently, our best candidates for such trapdoor OWF's are based on lattice problems, like the Shortest Vector Problem (SVP) that I described earlier. Whereas factoring reduces to the abelian hidden subgroup problem, which is solvable in quantum polynomial time, SVP is only known to reduce to the dihedral hidden subgroup problem, which is not known to be solvable in quantum polynomial time despite a decade of effort.
Inspired by this observation, and building on earlier work by Ajtai and Dwork, Oded Regev has recently proposed public-key cryptosystems that are provably secure against quantum eavesdroppers, assuming SVP is hard for quantum computers. Note that his cryptosystems themselves are purely classical. On the other hand, even if you only wanted security against classical eavesdroppers, you'd still have to assume that SVP was hard for quantum computers, since the reduction from SVP to breaking the cryptosystem is a quantum reduction!
A decade ago, the key and message lengths of these lattice-based cryptosystems were so impractical it was almost a joke. But today, largely because of Regev's work, that's no longer true. I'm still waiting for the first commercial implementations of his cryptosystems.
Question from the floor: What about elliptic-curve cryptosystems?
Answer: Yeah, those are still easily breakable by quantum computers, since the problem of breaking them can be expressed as an abelian hidden subgroup problem. (Elliptic curve groups are abelian.) On the other hand, the best-known classical algorithms for breaking elliptic curve cryptosystems apparently have much higher running times than the Number Field Sieve for breaking RSA -- it's a question of ~2n versus ~2n^1/3. That could be fundamental, or it could just be because algorithms for elliptic curve groups haven't been studied as much.
Thus completes our whirlwind tour of classical complexity and cryptography. I'll be in Europe for the next 10 days and hence the next three lectures are cancelled. We'll reconvene on Thursday, October 19, at which point we'll talk about quantum mechanics and Roger Penrose's The Emperor's New Mind. I'll expect everyone to have read the book by then. But if you read the "sequel," Shadows of the Mind, then you receive negative credit. You have to read another book, say The Road to Reality, in order to compensate for the damage you caused to yourself.
[Discussion of this lecture on blog]