The Power of the Digi-Comp II: My First Conscious Paperlet
Foreword: Right now, I have a painfully-large stack of unwritten research papers. Many of these are “paperlets”: cool things I noticed that I want to tell people about, but that would require a lot more development before they became competitive for any major theoretical computer science conference. And what with the baby, I simply don’t have time anymore for the kind of obsessive, single-minded, all-nighter-filled effort needed to bulk my paperlets up. So starting today, I’m going to try turning some of my paperlets into blog posts. I don’t mean advertisements or sneak previews for papers, but replacements for papers: blog posts that constitute the entirety of what I have to say for now about some research topic. “Peer reviewing” (whether signed or anonymous) can take place in the comments section, and “citation” can be done by URL. The hope is that, much like with 17th-century scientists who communicated results by letter, this will make it easier to get my paperlets done: after all, I’m not writing Official Papers, just blogging for colleagues and friends.
Of course, I’ve often basically done this before—as have many other academic bloggers—but now I’m going to go about it more consciously. I’ve thought for years that the Internet would eventually change the norms of scientific publication much more radically than it so far has: that yes, instant-feedback tools like blogs and StackExchange and MathOverflow might have another decade or two at the periphery of progress, but their eventual destiny is at the center. And now that I have tenure, it hit me that I can do more than prognosticate about such things. I’ll start small: I won’t go direct-to-blog for big papers, papers that cry out for LaTeX formatting, or joint papers. I certainly won’t do it for papers with students who need official publications for their professional advancement. But for things like today’s post—on the power of a wooden mechanical computer now installed in the lobby of the building where I work—I hope you agree that the Science-by-Blog Plan fits well.
Oh, by the way, happy July 4th to American readers! I hope you find that a paperlet about the logspace-interreducibility of a few not-very-well-known computational models captures everything that the holiday is about.
The Power of the Digi-Comp II
by Scott Aaronson
Abstract
I study the Digi-Comp II, a wooden mechanical computer whose only moving parts are balls, switches, and toggles. I show that the problem of simulating (a natural abstraction of) the Digi-Comp, with a polynomial number of balls, is complete for CC (Comparator Circuit), a complexity class defined by Subramanian in 1990 that sits between NL and P. This explains why the Digi-Comp is capable of addition, multiplication, division, and other arithmetical tasks, and also implies new tasks of which the Digi-Comp is capable (and that indeed are complete for it), including the Stable Marriage Problem, finding a lexicographically-first perfect matching, and the simulation of other Digi-Comps. However, it also suggests that the Digi-Comp is not a universal computer (not even in the circuit sense), making it a very interesting way to fall short of Turing-universality. I observe that even with an exponential number of balls, simulating the Digi-Comp remains in P, but I leave open the problem of pinning down its complexity more precisely.
Introduction
To celebrate his 60th birthday, my colleague Charles Leiserson (who some of you might know as the “L” in the CLRS algorithms textbook) had a striking contraption installed in the lobby of the MIT Stata Center. That contraption, pictured below, is a custom-built, supersized version of a wooden mechanical computer from the 1960s called the Digi-Comp II, now manufactured and sold by a company called Evil Mad Scientist.

Click here for a short video showing the Digi-Comp’s operation (and here for the user’s manual). Basically, the way it works is this: a bunch of balls (little steel balls in the original version, pool balls in the supersized version) start at the top and roll to the bottom, one by one. On their way down, the balls may encounter black toggles, which route each incoming ball either left or right. Whenever this happens, the weight of the ball flips the toggle to the opposite setting: so for example, if a ball goes left, then the next ball to encounter the same toggle will go right, and the ball after that will go left, and so on. The toggles thus maintain a “state” for the computer, with each toggle storing one bit.
Besides the toggles, there are also “switches,” which the user can set at the beginning to route every incoming ball either left or right, and whose settings aren’t changed by the balls. And then there are various wooden tunnels and ledges, whose function is simply to direct the balls in a desired way as they roll down. A ball could reach different locations, or even the same location in different ways, depending on the settings of the toggles and switches above that location. On the other hand, once we fix the toggles and switches, a ball’s motion is completely determined: there’s no random or chaotic element.
“Programming” is done by configuring the toggles and switches in some desired way, then loading a desired number of balls at the top and letting them go. “Reading the output” can be done by looking at the final configuration of some subset of the toggles.
Whenever a ball reaches the bottom, it hits a lever that causes the next ball to be released from the top. This ensures that the balls go through the device one at a time, rather than all at once. As we’ll see, however, this is mainly for aesthetic reasons, and maybe also for the mechanical reason that the toggles wouldn’t work properly if two or more balls hit them at once. The actual logic of the machine doesn’t care about the timing of the balls; the sheer number of balls that go through is all that matters.
The Digi-Comp II, as sold, contains a few other features: most notably, toggles that can be controlled by other toggles (or switches). But I’ll defer discussion of that feature to later. As we’ll see, we already get a quite interesting model of computation without it.
One final note: of course the machine that’s sold has a fixed size and a fixed geometry. But for theoretical purposes, it’s much more interesting to consider an arbitrary network of toggles and switches (not necessarily even planar!), with arbitrary size, and with an arbitrary number of balls fed into it. (I’ll give a more formal definition in the next section.)
The Power of the Digi-Comp
So, what exactly can the Digi-Comp do? As a first exercise, you should convince yourself that, by simply putting a bunch of toggles in a line and initializing them all to “L” (that is, Left), it’s easy to set up a binary counter. In other words, starting from the configuration, say, LLL (in which three toggles all point left), as successive balls pass through we can enter the configurations RLL, LRL, RRL, etc. If we interpret L as 0 and R as 1, and treat the first bit as the least significant, then we’re simply counting from 0 to 7 in binary. With 20 toggles, we could instead count to 1,048,575.
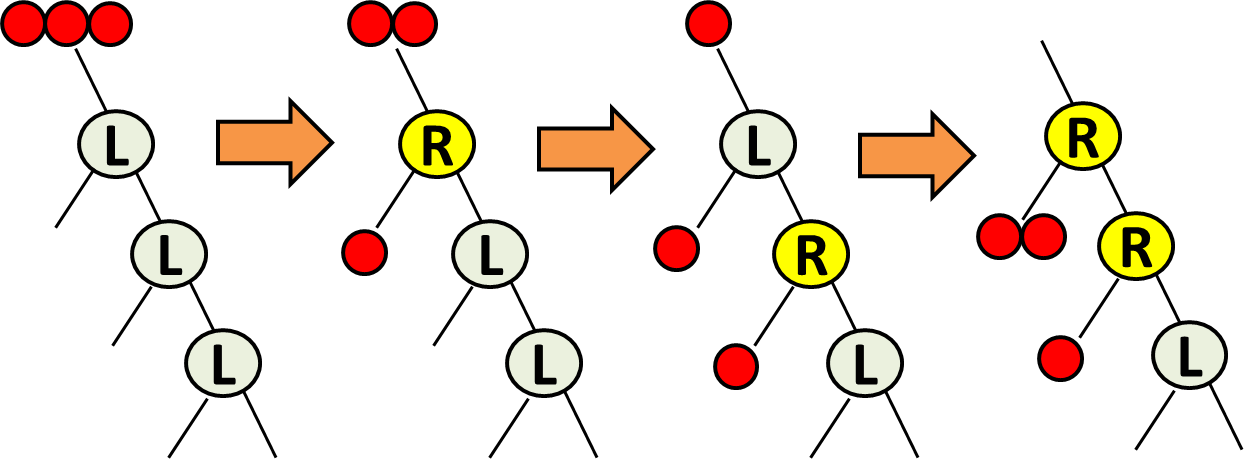
But counting is not the most interesting thing we can do. As Charles eagerly demonstrated to me, we can also set up the Digi-Comp to perform binary addition, binary multiplication, sorting, and even long division. (Excruciatingly slowly, of course: the Digi-Comp might need even more work to multiply 3×5, than existing quantum computers need to factor the result!)
To me, these demonstrations served only as proof that, while Charles might call himself a theoretical computer scientist, he’s really a practical person at heart. Why? Because a theorist would know that the real question is not what the Digi-Comp can do, but rather what it can’t do! In particular, do we have a universal computer on our hands here, or not?
If the answer is yes, then it’s amazing that such a simple contraption of balls and toggles could already take us over the threshold of universality. Universality would immediately explain why the Digi-Comp is capable of multiplication, division, sorting, and so on. If, on the other hand, we don’t have universality, that too is extremely interesting—for we’d then face the challenge of explaining how the Digi-Comp can do so many things without being universal.
It might be said that the Digi-Comp is certainly not a universal computer, since if nothing else, it’s incapable of infinite loops. Indeed, the number of steps that a given Digi-Comp can execute is bounded by the number of balls, while the number of bits it can store is bounded by the number of toggles: clearly we don’t have a Turing machine. This is true, but doesn’t really tell us what we want to know. For, as discussed in my last post, we can consider not only Turing-machine universality, but also the weaker (but still interesting) notion of circuit-universality. The latter means the ability to simulate, with reasonable efficiency, any Boolean circuit of AND, OR, and NOT gates—and hence, in particular, to compute any Boolean function on any fixed number of input bits (given enough resources), or to simulate any polynomial-time Turing machine (given polynomial resources).
The formal way to ask whether something is circuit-universal, is to ask whether the problem of simulating the thing is P-complete. Here P-complete (not to be confused with NP-complete!) basically means the following:
There exists a polynomial p such that any S-step Turing machine computation—or equivalently, any Boolean circuit with at most S gates—can be embedded into our system if we allow the use of poly(S) computing elements (in our case, balls, toggles, and switches).
Of course, I need to tell you what I mean by the weasel phrase “can be embedded into.” After all, it wouldn’t be too impressive if the Digi-Comp could “solve” linear programming, primality testing, or other highly-nontrivial problems, but only via “embeddings” in which we had to do essentially all the work, just to decide how to configure the toggles and switches! The standard way to handle this issue is to demand that the embedding be “computationally simple”: that is, we should be able to carry out the embedding in L (logarithmic space), or some other complexity class believed to be much smaller than the class (P, in this case) for which we’re trying to prove completeness. That way, we’ll be able to say that our device really was “doing something essential”—i.e., something that our embedding procedure couldn’t efficiently do for itself—unless the larger complexity class collapses with the smaller one (i.e., unless L=P).
So then, our question is whether simulating the Digi-Comp II is a P-complete problem under L-reductions, or alternatively, whether the problem is in some complexity class believed to be smaller than P. The one last thing we need is a formal definition of “the problem of simulating the Digi-Comp II.” Thus, let DIGICOMP be the following problem:
We’re given as inputs:
- A directed acyclic graph G, with n vertices. There is a designated vertex with indegree 0 and outdegree 1 called the “source,” and a designated vertex with indegree 1 and outdegree 0 called the “sink.” Every internal vertex v (that is, every vertex with both incoming and outgoing edges) has exactly two outgoing edges, labeled “L” (left) and “R” (right), as well as one bit of internal state s(v)∈{L,R}.
- For each vertex v, an “initial” value for its internal state s(v).
- A positive integer T (encoded in unary notation), representing the number of balls dropped successively from the source vertex.
Computation proceeds as follows: each time a ball appears at the source vertex, it traverses the path induced by the L and R states of the vertices that it encounters, until it reaches a terminal vertex, which might or might not be the sink. As the ball traverses the path, it flips s(v) for each vertex v that it encounters: L goes to R and R goes to L. Then the next ball is dropped in.
The problem is to decide whether any balls reach the sink.
Here the internal vertices represent toggles, and the source represents the chute at the top from which the balls drop. Switches aren’t included, since (by definition) the reduction can simply fix their values to “L” to “R” and thereby simplify the graph.
Of course we could consider other problems: for example, the problem of deciding whether an odd number of balls reach the sink, or of counting how many balls reach the sink, or of computing the final value of every state-variable s(v). However, it’s not hard to show that all of these problems are interreducible with the DIGICOMP problem as defined above.
The Class CC
My main result, in this paperlet, is to pin down the complexity of the DIGICOMP problem in terms of a complexity class called CC (Comparator Circuit): a class that’s obscure enough not to be in the Complexity Zoo (!), but that’s been studied in several papers. CC was defined by Subramanian in his 1990 Stanford PhD thesis; around the same time Mayr and Subramanian showed the inclusion NL ⊆ CC (the inclusion CC ⊆ P is immediate). Recently Cook, Filmus, and Lê revived interest in CC with their paper The Complexity of the Comparator Circuit Value Problem, which is probably the best current source of information about this class.
OK, so what is CC? Informally, it’s the class of problems that you can solve using a comparator circuit, which is a circuit that maps n bits of input to n bits of output, and whose only allowed operation is to sort any desired pair of bits. That is, a comparator circuit can repeatedly apply the transformation (x,y)→(x∧y,x∨y), in which 00, 01, and 11 all get mapped to themselves, while 10 gets mapped to 01. Note that there’s no facility in the circuit for copying bits (i.e., for fanout), so sorting could irreversibly destroy information about the input. In the comparator circuit value problem (or CCV), we’re given as input a description of a comparator circuit C, along with an input x∈{0,1}n and an index i∈[n]; then the problem is to determine the final value of the ith bit when C is applied to x. Then CC is simply the class of all languages that are L-reducible to CCV.

As Cook et al. discuss, there are various other characterizations of CC: for example, rather than using a complete problem, we can define CC directly as the class of languages computed by uniform families of comparator circuits. More strikingly, Mayr and Subramanian showed that CC has natural complete problems, which include (decision versions of) the famous Stable Marriage Problem, as well as finding the lexicographically first perfect matching in a bipartite graph. So perhaps the most appealing definition of CC is that it’s “the class of problems that can be easily mapped to the Stable Marriage Problem.”
It’s a wide-open problem whether CC=NL or CC=P: as usual, one can give oracle separations, but as far as anyone knows, either equality could hold without any dramatic implications for “standard” complexity classes. (Of course, the conjunction of these equalities would have a dramatic implication.) What got Cook et al. interested was that CC isn’t even known to contain (or be contained in) the class NC of parallelizable problems. In particular, linear-algebra problems in NC, like determinant, matrix inversion, and iterated matrix multiplication—not to mention other problems in P, like linear programming and greatest common divisor—might all be examples of problems that are efficiently solvable by Boolean circuits, but not by comparator circuits.
One final note about CC. Cook et al. showed the existence of a universal comparator circuit: that is, a single comparator circuit C able to simulate any other comparator circuit C’ of some fixed size, given a description of C’ as part of its input.
DIGICOMP is CC-Complete
I can now proceed to my result: that, rather surprisingly, the Digi-Comp II can solve exactly the problems in CC, giving us another characterization of that class.
I’ll prove this using yet another model of computation, which I call the pebbles model. In the pebbles model, you start out with a pile of x pebbles; the positive integer x is the “input” to your computation. Then you’re allowed to apply a straight-line program that consists entirely of the following two operations:
- Given any pile of y pebbles, you can split it into two piles consisting of ⌈y/2⌉ and ⌊y/2⌋ pebbles respectively.
- Given any two piles, consisting of y and z pebbles respectively, you can combine them into a single pile consisting of y+z pebbles.
Your program “accepts” if and only if some designated output pile contains at least one pebble (or, in a variant that can be shown to be equivalent, if it contains an odd number of pebbles).
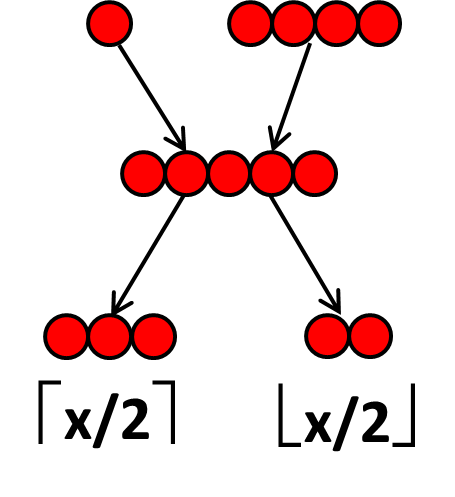
As suggested by the imagery, you don’t get to make “backup copies” of the piles before splitting or combining them: if, for example, you merge y with z to create y+z, then y isn’t also available to be split into ⌈y/2⌉ and ⌊y/2⌋.
Note that the ceiling and floor functions are the only “nonlinear” elements of the pebbles model: if not for them, we’d simply be applying a sequence of linear transformations.
I can now divide my CC-completeness proof into two parts: first, that DIGICOMP (i.e., the problem of simulating the Digi-Comp II) is equivalent to the pebbles model, and second, that the pebbles model is equivalent to comparator circuits.
Let’s first show the equivalence between DIGICOMP and pebbles. The reduction is simply this: in a given Digi-Comp, each edge will be associated to a pile, with the number of pebbles in the pile equal to the total number of balls that ever traverse that edge. Thus, we have T balls dropped in to the edge incident to the source vertex, corresponding to an initial pile with T pebbles. Multiple edges pointing to the same vertex (i.e., fan-in) can be modeled by combining the associated piles into a single pile. Meanwhile, a toggle has the effect of splitting a pile: if y balls enter the toggle in total, then ⌈y/2⌉ balls will ultimately exit in whichever direction the toggle was pointing initially (whether left or right), and ⌊y/2⌋ balls will ultimately exit in the other direction. It’s clear that this equivalence works in both directions: not only does it let us simulate any given Digi-Comp by a pebble program, it also lets us simulate any pebble program by a suitably-designed Digi-Comp.
OK, next let’s show the equivalence between pebbles and comparator circuits. As a first step, given any comparator circuit, I claim that we can simulate it by a pebble program. The way to do it is simply to use a pile of 0 pebbles to represent each “0” bit, and a pile of 1 pebble to represent each “1” bit. Then, any time we want to sort two bits, we simply merge their corresponding piles, then split the result back into two piles. The result? 00 gets mapped to 00, 11 gets mapped to 11, and 01 and 10 both get mapped to one pebble in the ⌈y/2⌉ pile and zero pebbles in the ⌊y/2⌋ pile. At the end, a given pile will have a pebble in it if and only if the corresponding output bit in the comparator circuit is 1.
One might worry that the input to a comparator circuit is a sequence of bits, whereas I said before that the input to a pebble program is just a single pile. However, it’s not hard to see that we can deal with this, without leaving the world of logspace reductions, by breaking up an initial pile of n pebbles into n piles each of zero pebbles or one pebble, corresponding to any desired n-bit string (along with some extra pebbles, which we subsequently ignore). Alternatively, we could generalize the pebbles model so that the input can consist of multiple piles. One can show, by a similar “breaking-up” trick, that this wouldn’t affect the pebbles model’s equivalence to the DIGICOMP problem.
Finally, given a pebble program, I need to show how to simulate it by a comparator circuit. The reduction works as follows: let T be the number of pebbles we’re dealing with (or even just an upper bound on that number). Then each pile will be represented by its own group of T wires in the comparator circuit. The Hamming weight of those T wires—i.e., the number of them that contain a ‘1’ bit—will equal the number of pebbles in the corresponding pile.
To merge two piles, we first merge the corresponding groups of T wires. We then use comparator gates to sort the bits in those 2T wires, until all the ‘1’ bits have been moved into the first T wires. Finally, we ignore the remaining T wires for the remainder of the computation.
To split a pile, we first use comparator gates to sort the bits in the T wires, until all the ‘1’ bits have been moved to the left. We then route all the odd-numbered wires into “Pile A” (the one that’s supposed to get ⌈y/2⌉ pebbles), and route all the even-numbered wires into “Pile B” (the one that’s supposed to get ⌊y/2⌋ pebbles). Finally, we introduce T additional wires with 0’s in them, so that piles A and B have T wires each.
At the end, by examining the leftmost wire in the group of wires corresponding to the output pile, we can decide whether that pile ends up with any pebbles in it.
Since it’s clear that all of the above transformations can be carried out in logspace (or even smaller complexity classes), this completes the proof that DIGICOMP is CC-complete under L-reductions. As corollaries, the Stable Marriage and lexicographically-first perfect matching problems are L-reducible to DIGICOMP—or informally, are solvable by easily-described, polynomial-size Digi-Comp machines (and indeed, characterize the power of such machines). Combining my result with the universality result of Cook et al., a second corollary is that there exists a “universal Digi-Comp”: that is, a single Digi-Comp D that can simulate any other Digi-Comp D’ of some polynomially-smaller size, so long as we initialize some subset of the toggles in D to encode a description of D’.
How Does the Digi-Comp Avoid Universality?
Let’s now step back and ask: given that the Digi-Comp is able to do so many things—division, Stable Marriage, bipartite matching—how does it fail to be a universal computer, at least a circuit-universal one? Is the Digi-Comp a counterexample to the oft-repeated claims of people like Stephen Wolfram, about the ubiquity of universal computation and the difficulty of avoiding it in any sufficiently complex system? What would need to be added to the Digi-Comp to make it circuit-universal? Of course, we can ask the same questions about pebble programs and comparator circuits, now that we know that they’re all computationally equivalent.
The reason for the failure of universality is perhaps easiest to see in the case of comparator circuits. As Steve Cook pointed out in a talk, comparator circuits are “1-Lipschitz“: that is, if you have a comparator circuit acting on n input bits, and you change one of the input bits, your change can affect at most one output bit. Why? Well, trace through the circuit and use induction. So in particular, there’s no amplification of small effects in comparator circuits, no chaos, no sensitive dependence on initial conditions, no whatever you want to call it. Now, while chaos doesn’t suffice for computational universality, at least naïvely it’s a necessary condition, since there exist computations that are chaotic. Of course, this simpleminded argument can’t be all there is to it, since otherwise we would’ve proved CC≠P. What the argument does show is that, if CC=P, then the encoding of a Boolean circuit into a comparator circuit (or maybe into a collection of such circuits) would need to be subtle and non-obvious: it would need to take computations with the potential for chaos, and reduce them to computations without that potential.
Once we understand this 1-Lipschitz business, we can also see it at work in the pebbles model. Given a pebble program, suppose someone surreptitiously removed a single pebble from one of the initial piles. For want of that pebble, could the whole kingdom be lost? Not really. Indeed, you can convince yourself that the output will be exactly the same as before, except that one output pile will have one fewer pebble than it would have otherwise. The reason is again an induction: if you change x by 1, that affects at most one of ⌈x/2⌉ and ⌊x/2⌋ (and likewise, merging two piles affects at most one pile).
We now see the importance of the point I made earlier, about there being no facility in the piles model for “copying” a pile. If we could copy piles, then the 1-Lipschitz property would fail. And indeed, it’s not hard to show that in that case, we could implement AND, OR, and NOT gates with arbitrary fanout, and would therefore have a circuit-universal computer. Likewise, if we could copy bits, then comparator circuits—which, recall, map (x,y) to (x∧y,x∨y)—would implement AND, OR, and NOT with arbitrary fanout, and would be circuit-universal. (If you’re wondering how to implement NOT: one way to do it is to use what’s known in quantum computing as the “dual-rail representation,” where each bit b is encoded by two bits, one for b and the other for ¬b. Then a NOT can be accomplished simply by swapping those bits. And it’s not hard to check that comparator gates in a comparator circuit, and combining and splitting two piles in a pebble program, can achieve the desired updates to both the b rails and the ¬b rails when an AND or OR gate is applied. However, we could also just omit NOT gates entirely, and use the fact that computing the output of even a monotone Boolean circuit is a P-complete problem under L-reductions.)
In summary, then, the inability to amplify small effects seems like an excellent candidate for the central reason why the power of comparator circuits and pebble programs hits a ceiling at CC, and doesn’t go all the way up to P. It’s interesting, in this connection, that while transistors (and before them, vacuum tubes) can be used to construct logic gates, the original purpose of both of them was simply to amplify information: to transform a small signal into a large one. Thus, we might say, comparator circuits and pebble programs fail to be computationally universal because they lack transistors or other amplifiers.
I’d like to apply exactly the same analysis to the Digi-Comp itself: that is, I’d like to say that the reason the Digi-Comp fails to be universal (unless CC=P) is that it, too, lacks the ability to amplify small effects (wherein, for example, the drop of a single ball would unleash a cascade of other balls). In correspondence, however, David Deutsch pointed out a problem: namely, if we just watch a Digi-Comp in action, then it certainly looks like it has an amplification capability! Consider, for example, the binary counter discussed earlier. Suppose a column of ten toggles is in the configuration RRRRRRRRRR, representing the integer 1023. Then the next ball to fall down will hit all ten toggles in sequence, resetting them to LLLLLLLLLL (and thus, resetting the counter to 0). Why isn’t this precisely the amplification of a small effect that we were looking for?
Well, maybe it’s amplification, but it’s not of a kind that does what we want computationally. One way to see the difficulty is that we can’t take all those “L” settings we’ve produced as output, and feed them as inputs to further gates in an arbitrary way. We could do it if the toggles were arranged in parallel, but they’re arranged serially, so that flipping any one toggle inevitably has the potential also to flip the toggles below it. Deutsch describes this as a “failure of composition”: in some sense, we do have a fan-out or copying operation, but the design of the Digi-Comp prevents us from composing the fan-out operation with other operations in arbitrary ways, and in particular, in the ways that would be needed to simulate any Boolean circuit.
So, what features could we add to the Digi-Comp to make it universal? Here’s the simplest possibility I was able to come up with: suppose that, scattered throughout the device, there were balls precariously perched on ledges, in such a way that whenever one was hit by another ball, it would get dislodged, and both balls would continue downward. We could, of course, chain several of these together, so that the two balls would in turn dislodge four balls, the four would dislodge eight, and so on. I invite you to check that this would provide the desired fan-out gate, which, when combined with AND, OR, and NOT gates that we know how to implement (e.g., in the dual-rail representation described previously), would allow us to simulate arbitrary Boolean circuits. In effect, the precariously perched balls would function as “transistors” (of course, painfully slow transistors, and ones that have to be laboriously reloaded with a ball after every use).
As a second possibility, Charles Leiserson points out to me that the Digi-Comp, as sold, has a few switches and toggles that can be controlled by other toggles. Depending on exactly how one modeled this feature, it’s possible that it, too, could let us implement arbitrary fan-out gates, and thereby boost the Digi-Comp up to circuit-universality.
Open Problems
My personal favorite open problem is this:
What is the complexity of simulating a Digi-Comp II if the total number of balls dropped in is exponential, rather than polynomial? (In other words, if the positive integer T, representing the number of balls, is encoded in binary rather than in unary?)
From the equivalence between the Digi-Comp and pebble programs, we can already derive a conclusion about the above problem that’s not intuitively obvious: namely, that it’s in P. Or to say it another way: it’s possible to predict the exact state of a Digi-Comp with n toggles, after T balls have passed through it, using poly(n, log T) computation steps. The reason is simply that, if there are T balls, then the total number of balls that pass through any given edge (the only variable we need to track) can be specified using log2T bits. This, incidentally, gives us a second sense in which the Digi-Comp is not a universal computer: namely, even if we let the machine “run for exponential time” (that is, drop exponentially many balls into it), unlike a conventional digital computer it can’t possibly solve all problems in PSPACE, unless P=PSPACE.
However, this situation also presents us with a puzzle: if we let DIGICOMPEXP be the problem of simulating a Digi-Comp with an exponential number of balls, then it’s clear that DIGICOMPEXP is hard for CC and contained in P, but we lack any information about its difficulty more precise than that. At present, I regard both extremes—that DIGICOMPEXP is in CC (and hence, no harder than ordinary DIGICOMP), and that it’s P-complete—as within the realm of possibility (along with the possibility that DIGICOMPEXP is intermediate between the two).
By analogy, one can also consider comparator circuits where the entities that get compared are integers from 1 to T rather than bits—and one can then consider the power of such circuits, when T is allowed to grow exponentially. In email correspondence, however, Steve Cook sent me a proof that such circuits have the same power as standard, Boolean comparator circuits. It’s not clear whether this tells us anything about the power of a Digi-Comp with exponentially many balls.
A second open problem is to formalize the feature of Digi-Comp that Charles mentioned—namely, toggles and switches controlled by other toggles—and see whether, under some reasonable formalization, that feature bumps us up to P-completeness (i.e., to circuit-universality). Personally, though, I confess I’d be even more interested if there were some feature we could add to the machine that gave us a larger class than CC, but that still wasn’t all of P.
A third problem is to pin down the power of Digi-Comps (or pebble programs, or comparator circuits) that are required to be planar. While my experience with woodcarving is limited, I imagine that planar or near-planar graphs are a lot easier to carve than arbitrary graphs (even if the latter present no problems of principle).
A fourth problem has to do with the class CC in general, rather than the Digi-Comp in particular, but I can’t resist mentioning it. Let CCEXP be the complexity class that’s just like CC, but where the comparator circuit (or pebble program, or Digi-Comp) is exponentially large and specified only implicitly (that is, by a Boolean circuit that, given as input a binary encoding of an integer i, tells you the ith bit of the comparator circuit’s description). Then it’s easy to see that PSPACE ⊆ CCEXP ⊆ EXP. Do we have CCEXP = PSPACE or CCEXP = EXP? If not, then CCEXP would be the first example I’ve ever seen of a natural complexity class intermediate between PSPACE and EXP.
Acknowledgments
I thank Charles Leiserson for bringing the Digi-Comp II to MIT, and thereby inspiring this “research.” I also thank Steve Cook, both for giving a talk that first brought the complexity class CC to my attention, and for helpful correspondence. Finally I thank David Deutsch for the point about composition.
 Follow
Follow
Comment #1 July 4th, 2014 at 11:50 am
It seems like circuits consisting of only ‘and’ and ‘or’ would be in CC because to sort 2 bits you can ‘and’ then ‘or’ them.
If so then unraveling knotted strings is in CC because it is posible to tie a knot such that it unravels if any of the strings it is tied around do, and it is possible to tie on that unravels only if all the strings it is tied around do. It is possible to copy things so I don’t know if that puts this model out of CC.
Comment #2 July 4th, 2014 at 1:41 pm
I must read all, but if the ball reach the bottom, and the lever carries the ball to the start (with a lift), then it is possible a cycle (a single ball Digi-Comp II with a lift), and the states of the toggles could be the state of a Turing string of finite lenght, with the halt problem.
Comment #3 July 4th, 2014 at 1:50 pm
anders #1: First of all, the general unknottedness problem is not even known to be in P, let alone CC! (Indeed, it was a major achievement of Haken in 1961 just to show that the problem was decidable…) If you’re talking about some special case of the unknottedness problem, then maybe you could specify which one.
Second, as I said, it’s a huge part of the definition of CC that you’re not allowed to copy bits, something that severely restricts the usefulness of the “AND” and “OR” gates that you implicitly have. Indeed, if you add an unrestricted copy gate, then you immediately jump up from CC to P.
Comment #4 July 4th, 2014 at 1:53 pm
domenico #2: As I discuss in the last two sections, there are many ways you could imagine enhancing the Digi-Comp in order to make it universal (at least circuit-universal, if not Turing-universal). Interestingly, however, I don’t know whether the mere ability to “cycle” balls back to the top after they reach the bottom would be an example of such an enhancement. Doing so would give you the problem that I called DIGICOMPEXP, which might or might not be P-complete—all I know about it is that it’s contained in P and hard for CC.
Note, however, that because DIGICOMPEXP is in P, one thing I do know for sure is that the ability to cycle balls back to the top, even for an exponential number of steps, would not let you simulate exponentially many steps of a polynomial-space Turing machine, unless P=PSPACE. At the very most, with exponentially many balls you could maybe simulate a polynomial number of Turing machine steps.
Comment #5 July 4th, 2014 at 2:16 pm
Hi Scott. Why not post your paperlets to arxiv?
Comment #6 July 4th, 2014 at 2:53 pm
Gus #5: Yeah, I thought about that. The trouble is, if I’m going to post to the arXiv (or ECCC), then I’ll need a nice formatted LaTeX document with a bibliography, etc., so at that point, why not submit it to a conference or journal as well? But then before I know it, I’m back to writing a “serious paper,” and my writers’ block returns in full force.
The other problem might make you laugh by its triviality: it usually takes me at least one full day of painful effort to get figures to show up correctly in LaTeX, since after I make them in PowerPoint, I then need to export to EPS files, then export the EPS to PDF, and after I’ve done that, the image is almost always tiny or enormous, or cropped in some weird way, and the text in it is screwed up because of a fonts problem. Whereas embedding images into a blog post is trivial.
Having said that, if enough people think it’s important for me to do so, I suppose I’ll indeed convert this blog post to TeX, and futz around with the images until they show up correctly.
Comment #7 July 4th, 2014 at 2:54 pm
Congratulations for your decision. Everybody should do that.
Comment #8 July 4th, 2014 at 3:21 pm
Funny, I was just reflecting a few days ago on the fact that you had been edging closer and closer to a new way of publishing “papers” and that I could not imagine a more ferocious peer review process than the comments. And now here you go. Godspeed, you are an inspiration to us all.
Comment #9 July 4th, 2014 at 3:26 pm
chorasimilarity #7 and luca #8: Thanks!! It should go without saying that, if anyone has ferocious peer review comments, they should go ahead and provide them…
Comment #10 July 4th, 2014 at 3:28 pm
Cool stuff, but I confess to being a little disappointed. I thought you’d come up with a paperlet that satisfied the IIT criterion…
Comment #11 July 4th, 2014 at 3:44 pm
RS #10: LOL! I suppose that, every time someone makes a “conscious effort” or a “conscious choice,” we should ask to know the effort or choice’s Φ-value…
Comment #12 July 4th, 2014 at 4:18 pm
Hi Scott,
I really like your paperlet blog-publication format, but since I also hold the class CC close to my heart, let me add my voice to those suggesting an arXiv publication as well.
Comment #13 July 4th, 2014 at 5:24 pm
The bipartite problem can be solved efficiently using flow networks and maximum flow, and I believe that comparator circuits could also be implemented on such flow networks (with cost on the edges) using max flow min cost.
But you can’t implement NOT gates on such networks (if you could have a NOT gate, you could have a fanout too), you can only have AND/OR gates.
I wonder if such flow networks are therefore also equivalent to the digi-comp.
Comment #14 July 4th, 2014 at 5:35 pm
fred #13:
I wonder if such flow networks are therefore also equivalent to the digi-comp.
That’s an absolutely wonderful question—thanks!!
Finding the lexicographically-first perfect matching in a bipartite graph, which is known to be CC-complete, can clearly be reduced to finding the lexicographically-first maximum flow. So the latter problem is somewhere between CC and P. However, that of course leaves open the question of whether we can find a lexicographically-first max flow in CC. More importantly, it also leaves open what’s the structural complexity of finding any max flow (or, say, the value of the max flow), rather than just the lexicographically first max flow.
I just googled for what’s known about the structural complexity of the max-flow problem (as opposed to the time complexity), but my search came up completely empty. Can anyone reading this enlighten us?
Comment #15 July 4th, 2014 at 5:50 pm
Scott #14
I wasted quite a bit of energy naively thinking that such networks could implement logic gates http://arxiv.org/abs/1310.1971v5 (I finally saw the light after implementing the thing, following your advice).
I was never able to find much info on the computing capacity of such networks (or more accurately wasn’t able to correctly grasp it).
Comment #16 July 4th, 2014 at 6:02 pm
The cool part about your “1-Lipschitz buisness” is that n changes to the input bits also can cause a maximum of n changes to the output bits (this can be seen by simply applying them one at a time).
Comment #17 July 4th, 2014 at 6:34 pm
Scott #14
What I realized is that even if you augment the network with costs (say, each edge has a cost of 1), you can only minimize the total cost of the flow set, but not select among sets of same cost.
E.g. if the maxflow value is 2 (flows), and the min total cost/length is 8, with two possible solution flow sets: one with lengths {3,5} and one with lengths {4,4}, there is no (efficient) way to select one solution over the other (according to some sorting criteria, like {3,5}<{4,4}).
Comment #18 July 4th, 2014 at 11:45 pm
Scott,
>> replacements for papers: blog posts
I think there are 2 problems with your approach (in the long run):
i) persistence: Are you sure your blog will be around 10 years from now (and can people who reference your “paperlets” be)?
ii) search; If everybody would follow your example, we would not find the relevant literature to a certain topic by browsing the arxiv or certain journals, but we would have to use Google (and I for one don’t trust them) and deal with all kinds of different formats, layouts etc.
In other words, I would encourage you to upload your articles to the arxiv – like the untenured folks 😎
Comment #19 July 5th, 2014 at 12:10 am
You don’t need tex or a bibliography to post to the arxiv. If the diagrams started life in powerpoint, can you export them to word, add the text, and print to pdf?
Comment #20 July 6th, 2014 at 8:34 pm
Amateur question here: if I undestand the above, the DigiComp’s ball-switch-gravity design limits it from being “circuit complete”. That immediately reminded me of an equally-limited circuit design: diode logic.
http://en.wikipedia.org/wiki/Diode_logic
Diode logic is neat, because the components are entirely passive–you don’t need a power supply. (Until enough diodes attenuate the signal away.) But it’s limited in that you can’t make all logic gates with it: no NOT. Is this limitation the same as DigiComp’s? Or are these just two different designs that fail universal computation for different reasons?
Comment #21 July 6th, 2014 at 8:55 pm
JohnD #20: No, from the Wikipedia page, it looks like diode logic corresponds to what complexity theorists call monotone circuits (circuits with AND and OR gates, but no NOT gate), which are a very different type of non-universality than Digi-Comps / comparator circuits. On the one hand, the circuit value problem for monotone circuits is already P-complete (i.e., just as hard as it is for non-monotone circuits). On the other hand, for certain specific functions (like Clique and Maximum Matching), the monotone circuit complexity is so well understood that we know how to prove unconditional exponential lower bounds on circuit size—that was one of the great achievements of complexity in the 1980s, initiated by Razborov.
With comparator circuits, by contrast, the circuit value problem is not P-complete, but “merely” CC-complete. And you can even throw NOT gates into the circuit, and the problem remains CC-complete. After you’ve done that, you have a model that can implement AND, OR, and NOT, yet that still isn’t universal, basically because you’re restricted in how you can compose the operations (more specifically, you lack a fanout or COPY gate).
Whether one can prove interesting unconditional lower bounds on the sizes of comparator circuits or Digi-Comps is a superb question that hadn’t occurred to me before, but which is immediately suggested by the comparison with monotone circuits. Does anyone have thoughts? I mean, if we consider comparator circuits over a sufficiently-large non-Boolean domain, then there’s the famous Ω(n log n) lower bound for comparison-based sorting. But is there anything more interesting than that, and/or anything for Boolean comparator circuits?
Note added 2 minutes later: OK, thanks to Dana, I just learned about the zero-one principle for sorting networks, which allows you to “lift” the Ω(n log n) lower bound for comparison-based sorting from non-Boolean domains to the Boolean one. Whether one can prove an interesting lower bound on, e.g., the size of a comparator circuit needed for Stable Marriage or multiplication remains a question that interests me.
Comment #22 July 6th, 2014 at 10:08 pm
@Scott
Completely off-topic, but have you seen this paper by t’ Hofft?
http://arxiv.org/pdf/1405.1548v2.pdf
Comment #23 July 7th, 2014 at 7:54 am
Nyme #22: Yes, of course I saw it. Let me just paste an email I sent to a friend who asked me about it when it came out two months ago:
I only read a few parts of the 200-page manifesto, but it looked like mostly just a recap of what ‘t Hooft has been saying over and over for the last decade (or longer). He’s become a broken record on this matter.
Look, ‘t Hooft believes in a classical, deterministic cellular automaton underlying all of physics. So he then faces the obvious problem of how to account for known quantum phenomena such as Bell inequality violation in such a model. Originally, ‘t Hooft dealt with this problem by simply ignoring it (from reading his early papers, I think, to be honest, that he didn’t fully understand the Bell inequality!). But after enough people explained it to him, he adopted his current position: that the way out is “superdeterminism.” In other words, when Alice and Bob play (say) the CHSH game, and they win it 85% = cos2(π/8) of the time rather than just 3/4 of the time, they might think they’re doing something that Bell proved to be impossible in a classical, local-realistic universe. But actually, the initial conditions of the universe conspired so that Alice and Bob were never playing the game they thought they were!
I.e., there was a conspiracy involving Alice’s and Bob’s brains, the random-number generators in their computers, and the elementary particles so that Alice and Bob didn’t actually have the freedom they thought they had to choose the detector settings! Rather, the detector settings were secretly prearranged since the beginning of time — and all just to make it look like the CHSH game can be won 85% of the time! You’d think that such a magical ability would let Alice and Bob do something more impressive, like send signals faster than light, or (at the very least) win the CHSH game 90% or 100% of the time. But no, the sole purpose of this gigantic cosmic conspiracy is to make it look like ordinary textbook quantum mechanics is valid, at least for those experiments that have already been done.
To me, this sort of “explanation” is hardly better than the creationists’ God, who planted the fossils in the ground to confound the paleontologists. Indeed, it’s almost like a backhanded compliment to Bell, like a convoluted way of admitting that you’ve lost the argument. And crucially, it’s completely scientifically sterile: I don’t see how it helps us understand quantum mechanics better; for example, it offers no explanation for why the CHSH game happens to be winnable exactly 85% of the time (just like the creationists’ theory fails to why God would plant dinosaur fossils in the ground, rather than mermaid fossils or anything else). I don’t understand why anyone, least of all ‘t Hooft, would feel inclined to take such a convoluted non-explanation seriously.
Yet, in Section 14.3 of his new manifesto, ‘t Hooft explicitly affirms that this is indeed his view. Since he’d titled the section “Superdeterminism and Conspiracy,” I thought ‘t Hooft was going to explain there why the critics’ charges are false — why his view doesn’t require a ridiculous cosmic conspiracy, and isn’t anywhere near as absurd as the fossil-planting God. But no, he basically admits in that section that this is indeed the implication of his view, and we should just swallow it, since it’s the only way he sees to avoid quantum mechanics.
Comment #24 July 7th, 2014 at 1:27 pm
I believe I have a construction that shows that planar DIGICOMP is equivalent to arbitrary graph DIGICOMP. In terms of the pebble game, the planarity requirement can be viewed as the statement that the piles are in a linear order, and piles can only be merged with their neighbors. If we take “planar” just to mean that the DAG lies entirely in the plane (with the source and sink possibly enclosed from the outer face, and a physical machine built in the shape of a cone), then the piles are in a ring; if we take “planar” to mean that the digicomp is actually flat, then the piles are in a line segment. These two will also become equivalent, but since the ring-planar version clearly includes the straight-planar version, I’ll deal with the latter.
Since the restriction states that we can only manipulate adjacent piles, our problem becomes that of finding a way to exchange two adjacent piles non-destructively. Suppose that we replace each pile of T balls with a pile of 2T balls. Now we have a pile with 2X and 2Y, let’s say, in that order, that we want to exchange. Split the 2Y pile into Y and Y, split both of those into ⌊Y/2⌋ and ⌈Y/2⌉, those into ⌊⌊Y/2⌋/2⌋ etc., and so on. At the end we have roughly Y piles, with the lowest ‘bit’ of Y on the left. This is necessarily either 0 or 1. We now merge this with the 2X pile. We do the same operation splitting there, of separating out the smallest ‘bit’, and then we merge all the other X piles. If the low bit of Y was 0, then we have 0 and 2X, in that order; if the low bit was 1, we have 1 and 2X. Thus we have exchanged a single pebble of Y and 2X. We then exchange 2X with the next pebble that may or may not be there, and then the next, and the next. Through this we can move all of Y through 2X. We can move the second Y through 2X by the same process, and then merge them on the other side. This lets us ‘exchange’ two of our double piles, because it’s easy for the pebbles to ignore doubles. In the DIGICOMP construction, this would be equivalent to having two pebbles from X at a time flow through a gate to the other side, leaving it unchanged at the end.
But now the two main operations of the pebbles, that of merging and splitting, need to be done on piles of twice the size. Merging is simple: 2X and 2Y become 2(X+Y). Splitting is a bit more tricky. Say we have 2X and 2Y and want to make 2⌊(X+Y)/2⌋ and 2⌈(X+Y)/2⌉. I think this is best done with a diagram:
{2X, 2Y}
{2X+2Y} (merge)
{X+Y, X+Y} (split)
{⌊(X+Y)/2⌋, ⌈(X+Y)/2⌉, ⌈(X+Y)/2⌉, ⌊(X+Y)/2⌋} (two splits, one going one way and one the other)
{⌊(X+Y)/2⌋, 2⌈(X+Y)/2⌉, ⌊(X+Y)/2⌋} (merge)
{⌊(X+Y)/2⌋, ⌊(X+Y)/2⌋, 2⌈(X+Y)/2⌉} (exchange, which is possible because 2⌈(X+Y)/2⌉ is even)
{2⌊(X+Y)/2⌋, 2⌈(X+Y)/2⌉} (merge)
This lets us do all the operations of regular pebbles, by using 2n pebbles. The exchange operations will take a number of gates polynomial in the number of pebbles (specifically, n log n), but this is still within the constraints.
On a mostly unrelated note: Has anyone looked at quantum version of CC — if that even exists — some set of gates that allow phase shifts and sorting? Does this sit at CC, explode into EQP (e.g. by allowing some way of encoding NOT in the phases), or sit somewhere in between?
Comment #25 July 7th, 2014 at 2:43 pm
Alexander #24: That’s an awesome construction—thanks so much! I went through it and I think that it works.
Now, regarding a quantum version of CC, one immediate problem is that sorting is a non-reversible, and therefore non-unitary, operation. One could deal with that using, e.g., the superoperator formalism, but it’s far from obvious to me what a good or interesting superoperator version of CC would be. Ideas welcome.
Comment #26 July 7th, 2014 at 5:16 pm
To make a quantum version of CC you could also try to make sorting reversible. SORT maps 00->00, 01->01, 10 ->01 and 11->11. By adding a ancilla bit in front we get RSORT; 000->000, 001->001, 010->101, 011->011, 100->100, 101->010, 110->110, 111->111.
RSORT is reversible and provided the first bit is a zero ancilla bit it will act on the last two bits as SORT does. If you discard the ancilla bit after use this will give you CC. Then you can use quantum gates as well.
If you do not discard the ancilla bit, so basically if you use RSORT as a regular gate, I think we get P. Because then you get to copy a bit in the following way; 1(your bit)1 -> 010 if your bit was 0 and 111 if your bit was 1. Then just take the first and last bit.
Anybody have any idea as to the power of RSORT with quantum gates (ancilla bits discarded after use)?
Comment #27 July 8th, 2014 at 1:07 pm
As my understanding goes, the act of “discarding” a bit is a somewhat forbidden operation in quantum computers. Indeed, if it weren’t, then /any/ function could be done by storing the original input in one set of bits, and the output in another set (this half is reversible), and then erasing the first half. When a bit is “erased” it really just gets the data entangled with the environment in a very complicated, pseudo-random way — one that alters the phase so unpredictably that quantum interference can no longer be intentionally, and you’re left with a branch of execution that’s just a probabilistic classical computer.
Comment #28 July 8th, 2014 at 1:39 pm
@Alexander #27, Well you do not erase the bits, you just ignore them for the rest of the computation.
Comment #29 July 8th, 2014 at 3:15 pm
My comment is offtopic but I’ve found interesting your idea of paperlets.
I like to know how people do their research work. I also think it might be interesting to other people, especially those who want to start a career as researchers.
Writing every idea is a fundamental habit for any researcher, but besides that, how do you read scientific books?, is it necessary to check all calculations?, do you take a lot of notes while reading?, and in the case of scientific papers?. A scientist has to conduct research but also to continue acquiring knowledge, how you manage time between these two needs?
I think a post about these topics would be very helpful.
Comment #30 July 8th, 2014 at 6:23 pm
If figures are really your bottleneck, I suggest using inkscape instead of powerpoint… it takes a few hours to learn and you can immediately get nice-looking pdf vector graphics that behave well under rescaling and are always small files. It never takes me longer than 10-15 minutes to produce a (simple) figure and put it into latex with the size I want.
Comment #31 July 8th, 2014 at 7:23 pm
Nosy #29: I don’t mind answering any of those questions, but that’s a lot of questions. You might want to check out my “Ask Me Anything” posts, and if the answers aren’t there, then wait for the next such post.
Daniel #30: Thanks for the tip! I’ve had coauthors who used TikZ to make graphics, which seemed to be very nice. Other tools that are on my stack to learn include Python, Matlab, Mathematica, and GAP. Alas, I feel like years ago I already became too old to learn new tricks…
Comment #32 July 8th, 2014 at 9:27 pm
I had a Digi-Comp II when I was a kid! Before that I had a Digi-Comp I, which you operated by moving a lever back and forth repeatedly. I actually thought the Digi-Comp I was a lot more fun, but maybe that was because I didn’t appreciate that the Digi-Comp II is CC-complete.
I really loved that Digi-Comp I. (Sniff …)
Comment #33 July 9th, 2014 at 5:04 am
If figures are your bottleneck, have you tried to supervise PhD students or even undergraduate students, and make them help you with the figures? Of course, supervising a PhD student will probably actually take more of your time than what you gain with the figures.
Comment #34 July 9th, 2014 at 10:11 am
I can show that PL (analogue to PP) is contained in DIGICOMP_EXP. This is strong evidence that DIGICOMP_EXP is unequal to CC.
The following problem is PL-complete: given a directed acyclic graph with specified start and end vertices, and given a natural number n, determine whether the number of paths from the start to the end node is greater than n. To solve this, first turn the graph into an equivalent graph with the following properties:
* The graph is graded so that every vertex is labelled with an integer.
* An edge must go from a vertex of level i to a vertex of level i+1.
* Every vertex has at most two edges leading out of it.
For convience say that the start vertex is in level 0 and the end vertex is level m-1.
This new graph is turned into the following pebble machine: 2^m pebbles are placed at the start vertex. The pebbles on each vertex split and go to the two vertices pointed from that vertex. All the pebbles leading to a vertex are unified. If a vertex has degree less than two the pile left over from the split is thrown away. Then can be seen that number of pebbles on a vertex in level i is 2^(m-i) times the number of paths leading there from the start vertex. Finally the pile at end vertex goes through a counter to see if there are more than n pebbles there.
Comment #35 July 9th, 2014 at 10:23 am
Itai #34: Extremely nice observation! I went through and think it works.
Given that PL ⊆ SPACE(log2), one immediate question raised by your observation is whether we can show DIGICOMPEXP ⊆ SPACE(log2) as well. That would give strong evidence that DIGICOMPEXP ≠ P.
Another question is whether we can give evidence that CC does not contain PL. I admit to lacking a strong intuition here.
Comment #36 July 9th, 2014 at 1:53 pm
Scott #6 Uh, maybe I’ve missed something here, but . . . why don’t you use the LaTeX document class Beamer instead of PowerPoint? What possible advantage does PowerPoint have over Beamer? Apologies for being off-topic on a nice little post.
Comment #37 July 9th, 2014 at 3:06 pm
ScentOfViolets #36: See comment #31 (this is not something I’m proud of).
Comment #38 July 12th, 2014 at 6:18 pm
Just to be clear — DIGICOMP_EXP is the same thing as CC_EXP? Or no?
Comment #39 July 12th, 2014 at 9:30 pm
Sniffnoy #38: Oops, sorry, I hadn’t even noticed that I’d overloaded the EXP notation! No, they’re not the same thing. DIGICOMPEXP is the problem of simulating a DigiComp with an exponential number of balls (but still a polynomial number of toggles), and is contained in P. CCEXP, by contrast, is the complexity class that corresponds to comparator circuits of exponential size—or equivalently, to DigiComps with exponentially many balls and exponentially many toggles. CCEXP sits somewhere between PSPACE and EXP, so (presumably) way above DIGICOMPEXP and P.
Comment #40 July 12th, 2014 at 11:16 pm
I see, thanks!
Comment #41 July 12th, 2014 at 11:27 pm
Scott #6: Is there a reason it *has* to be to PDF, and the text *has* to be selectable? If it doesn’t, you could always just use PNGs.
Comment #42 July 14th, 2014 at 1:00 pm
Congratulations for figuring out a way to circumvent the trivial inconvenience pitfall.
Comment #43 July 15th, 2014 at 6:29 pm
I can also prove an upper bound for DIGICOMP_EXP, namely, that it is contained in CC^#L. The key idea is that when a large number of pebbles go through a splitter it is fairly easy to tell what happens to most pebbles, nammely, they split equally. Because of this it is possible to divide the pebbles into two components: A bulk component which may have exponentially many pebbles but is relatively predictable and a residual component which can perform CC circuits but has a polynomially bounded number of pebbles. The residual component can depend on the bulk component but not vice versa.
Consider a simplified pebbles model where the amount of pebbles at a point may be rational numbers, and splitters turn a pile of x pebbles into two piles of x/2. Then the number of pebbles in any given point is always of the form n/2^l, where l is independent of the input and n is in #L. Consider the approximation which says that the number of pebbles at point is the floor of the value given by the simplified pebbles model. The true pebbles model differs from this approximation as follows:
* When two piles merge and the simplified pebble model gives them values x and y, this approximation says that the output value is floor(x+y). The value it should receive is floor(x)+floor(y), which is one less if frac(x)+frac(y) is greater than or equal to 1, and otherwise the same.
* When the simplified pebble model gives a value of x at a point which is followed by a split, this approximation says a pile of size floor(x) splits into two piles of size floor(x/2)=floor(floor(x)/2). However, one of the piles would be ceiling(floor(x)/2) in the true model, which is one pebble more if floor(x) is odd, and otherwise the same. For reasons that will be clear later, a better way to think of it is that in the simplified pebble model one pebble is removed from a pile before it splits if it is odd. Then the number of pebbles going through a splitter is always even.
In short, it is possible to obtain this approximation by taking an actual DIGICOMP_EXP computation and adding or removing at most one ball next to each gate, and the number of balls that needs to be added or removed can be calculated in CC^#L.
It seems like it should be possible to use order-independence of the pebble model to then calculate the actual DIGICOMP_EXP computation out of the simplified version. However, to make this work it is necessary to make use of anti-pebbles. Anti-pebbles move like ordinary pebbles, but when they merge with an ordinary pebble they are both destroyed. DIGICOMP with anti-pebbles is still order-independent, and allows you to ‘reverse’ a placement of a pebble of one sign by placing another pebble of the opposite sign. By starting with the simplified model and then placing pebbles of appropiate sign in the right places it is indeed possible to simulate DIGICOMP_EXP with polynomially many pebbles. Note that because in the simplified model an even number of pebbles always goes through a splitter it is not necessary to figure out the state of the splitters after the simplified model is execeuted.
Now the remaining task it to simulate DIGICOMP with polynomial pebbles but that some of them are anti-pebbles. This is equivalent to the pebble model where the number of pebbles is an arbitrary integer. However, a pile of size z can be represented as a pile of size n+z where n is an appropiately large even number. To split z, split n+z into n/2+floor(z/2) and n/2+ceiling(z/2) and add n/2 pebbles to each of these. To merge z and w, merge n+z and n+w into 2*n+z+w. Afterwards it is possible to use a pebbles circuit to subtract n from this, or alternately, in the model you made to show that pebbles is in CC it is possible to subtract n directly.
Comment #44 July 17th, 2014 at 1:31 pm
Itai #43:
Thanks; that’s extremely interesting! I’m sorry for the delay; only today did I have time to work through your proof. Alas, there are still a few points that I don’t understand.
the number of balls that needs to be added or removed can be calculated in CC^#L.
Can you be more explicit about this step? How do we do the calculation in CC#L? (What do we use the CC part for, and when does CC call the #L oracle?)
Also, I didn’t understand the part about anti-pebbles. I don’t understand why, once we have the above, we aren’t already done; I don’t understand why anti-pebbles solve the problem; and I don’t understand what the exact rules are governing the evolution of anti-pebbles. Do “anti-pebbles” just mean that the number of pebbles in a given pile is allowed to be an arbitrary integer, rather than a nonnegative one? But it’s still the case that merging a pile with x pebbles with a pile with y pebbles yields a pile with x+y pebbles, and that splitting a pile with x piles yields piles with floor(x/2) and ceiling(x/2) pebbles?
Comment #45 July 20th, 2014 at 6:29 am
I very strongly approve of this paperlet idea. I must follow your example and find the time to get some of the stuff that sits in my filespace to see the light of day: it’s something I’ve meant to do in one way or another for ages.
Comment #46 July 24th, 2014 at 10:32 pm
This is something Kannan and Vitaly Feldman might be interested in. “low-Lipschitz”-ness seems like a nice constructive way to lower-bound the sample complexity of statistical algorithms.
Comment #47 July 25th, 2014 at 5:36 pm
Scott #44: Thank you for responding. I’m also sorry for the delay, it’s just that I have a difficulty with writing in general.
Before I respond to your questions I want to take a chance to improve my own terminology. My simplification of DIGICOMP with rational numbers as pebble values was called in #43 “the simplified model”; I will instead call it “the rational approximation”. The floor of the rational approximation, which I previously called an “approximation”, will be called “the integer approximation”.
The important point about the rational approximation and the integer approximation is that they are both derived from a #L computation in a very simple manner. In turn, the number of balls that need to be added or removed is derived in relatively simple way from the value of the rational approximation, which is why it’s in #L. To be more precise, for merging piles it is necessary to compute frac(x)+frac(y) where x and y are the rational approximations of two piles. x and y are both of the form a/2^n for a in #L. Taking the fractional part of a/2^n is just taking away a certain number of digits from the left, and addition is in CC. Splitting is even easier; it requires taking the parity of floor(a/2^n), which is just the n’th digit from the right (counting from zero).
What we achieved so far is that we found a machine which follows the real rules of DIGICOMP but involves small known perturbations at each gate, and ends up with a result whose value we know. What we want to achieve is to figure out the output value for the DIGICOMP machine which doesn’t have any perturbations. In the case where the only perturbations are the removal of balls, getting one from the other is fairly easy. You can just place back all the balls that were removed earlier, taking advantage of the fact that DIGICOMP is invariant under changing the order of the balls. In a sense the balls are not actually removed, but merely delayed, and the result is the same as DIGICOMP computation without perturbations. In the case where balls are added as well a similar idea works, but requires the usage of anti-pebbles.
In the pebbles model, allowing anti-pebbles is equivalent to letting the number of pebbles be an arbitrary integer, just the way you guessed, and the pebble operations remain the same. I use this to show that DIGICOMP with anti-pebbles is in CC. However, I want to take advantage of order-independence, which is a property of the original DIGICOMP model and is harder to formulate in the pebbles model. That is why I invoked anti-pebbles and added them to the original DIGICOMP model. In retrospect it would have made more sense to call them “anti-balls”, to more clearly distinguish balls in the DIGICOMP model and pebbles in the pebbles model. The key property of anti-balls is that placing a ball a certain place and then placing an anti-ball does not change the state of the machine
By the way, I made a mistake when I originally described anti-balls. I stated that “anti-pebbles move like ordinary pebbles”, but actually, when an anti-ball goes through a splitter, it goes the opposite direction from where an ordinary ball would go (and also changes the state of the splitter like an ordinary ball). This might have been the cause of your confusion.
Finally,I want to point out that this argument actually gives a slightly stronger bound for DIGICOMP_EXP. This is because the calls to #L are only necessary for computing the rational approximation, and the parameters for this come directly from the input without any CC computation. I believe the name for the complexity class of this type of calculation is $latex \mathsf{CC} \cdot \sharp \mathsf{P}$. Similarly, my lower bound of PL can easily be improved to $latex \mathsf{CC} \cdot \mathsf{PL}$ by postprocessing the output of my PL circuit. Together these give a fairly tight constraint.
Comment #48 July 25th, 2014 at 8:27 pm
For another example of a “natural” system that is CC complete, mine-carts and powered rails in minecraft alone (say in pocket edition where that’s all you have) can simulate the toggling gates of a digicomp well. I don’t know if it’s possible to build something that has more computational power with minecraft pocket edition at the moment, however.
Comment #49 January 6th, 2015 at 11:38 am
I tried to find this back when this was first posted but I failed to find it. Then just the other day I stumbled upon it, so I thought I’d add it here. The question of the computational complexity of the Digicomp was investigated by someone else here a few months before this post. They don’t spend much time on the single toggle machines, but instead concentrate on the computational power when you add pairs of linked toggles. It turns out you can pretty cleanly construct a Turing machine (and he does so explicitly). It makes a nice companion to this post.
Comment #50 June 23rd, 2016 at 5:35 am
Sorry, but I don’t understand the breaking-up trick: how are the n pebbles to be distributed to n piles each of zero pebbles or one pebble. According to which “logic” should this happen? How is it decided which of the n piles gets a pebble and which one not?