Shtetl-OptimizedThe Blog of Scott Aaronson2024-04-24T16:48:05Zhttps://scottaaronson.blog/?feed=atomhttps://scottaaronson.blog/wp-content/uploads/2021/10/cropped-Jacket-32x32.gifScotthttp://www.scottaaronson.com<![CDATA[My Passover press release]]>https://scottaaronson.blog/?p=79572024-04-24T16:48:05Z2024-04-22T21:27:36ZFOR IMMEDIATE RELEASE – From the university campuses of Assyria to the thoroughfares of Ur to the palaces of the Hittite Empire, students across the Fertile Crescent have formed human chains, camel caravans, and even makeshift tent cities to protest the oppression of innocent Egyptians by the rogue proto-nation of “Israel” and its vengeful, warlike deity Yahweh. According to leading human rights organizations, the Hebrews, under the leadership of a bearded extremist known as Moses or “Genocide Moe,” have unleashed frogs, wild beasts, hail, locusts, cattle disease, and other prohibited collective punishments on Egypt’s civilian population, regardless of the humanitarian cost.
Human-rights expert Asenath Albanese says that “under international law, it is the Hebrews’ sole responsibility to supply food, water, and energy to the Egyptian populace, just as it was their responsibility to build mud-brick store-cities for Pharoah. Turning the entire Nile into blood, and plunging Egypt into neverending darkness, are manifestly inconsistent with the Israelites’ humanitarian obligations.”
Israelite propaganda materials have held these supernatural assaults to be justified by Pharoah’s alleged enslavement of the Hebrews, as well as unverified reports of his casting all newborn Hebrew boys into the Nile. Chanting “Let My People Go,” some Hebrew counterprotesters claim that Pharoah could end the plagues at any time by simply releasing those held in bondage.
Yet Ptahmose O’Connor, Chair of Middle East Studies at the University of Avaris, retorts that this simplistic formulation ignores the broader context. “Ever since Joseph became Pharoah’s economic adviser, the Israelites have enjoyed a position of unearned power and privilege in Egypt. Through underhanded dealings, they even recruited the world’s sole superpower—namely Adonai, Creator of the Universe—as their ally, removing any possibility that Adonai could serve as a neutral mediator in the conflict. As such, Egypt’s oppressed have a right to resist their oppression by any means necessary. This includes commonsense measures like setting taskmasters over the Hebrews to afflict them with heavy burdens, and dealing shrewdly with them lest they multiply.”
Professor O’Connor, however, dismissed the claims of drowned Hebrew babies as unverified rumors. “Infanticide accusations,” he explained, “have an ugly history of racism, Orientalism, and Egyptophobia. Therefore, unless you’re a racist or an Orientalist, the only possible conclusion is that no Hebrew babies have been drowned in the Nile, except possibly by accident, or of course by Hebrews themselves looking for a pretext to start this conflict.”
Meanwhile, at elite academic institutions across the region, the calls for justice have been deafening. “From the Nile to the Sea of Reeds, free Egypt from Jacob’s seeds!” students chanted. Some protesters even taunted passing Hebrew slaves with “go back to Canaan!”, though others were quick to disavow that message. According to Professor O’Connor, it’s important to clarify that the Hebrews don’t belong in Canaan either, and that finding a place where they do belong is not the protesters’ job.
In the face of such stridency, a few professors and temple priests have called the protests anti-Semitic. The protesters, however, dismiss that charge, pointing as proof to the many Hebrews and other Semitic peoples in their own ranks. For example, Sa-Hathor Goldstein, who currently serves as Pithom College’s Chapter President of Jews for Pharoah, told us that “we stand in solidarity with our Egyptian brethren, with the shepherds, goat-workers, and queer and mummified voices around the world. And every time Genocide Moe strikes down his staff to summon another of Yahweh’s barbaric plagues, we’ll be right there to tell him: Not In Our Name!”
“Look,” Goldstein added softly, “my own grandparents were murdered by Egyptian taskmasters. But the lesson I draw from my family’s tragic history is to speak up for oppressed people everywhere—even the ones who are standing over me with whips.”
“If Yahweh is so all-powerful,” Goldstein went on to ask, “why could He not devise a way to free the Israelites without a single Egyptian needing to suffer? Why did He allow us to become slaves in the first place? And why, after each plague, does He harden Pharoah’s heart against our release? Not only does that tactic needlessly prolong the suffering of Israelites and Egyptians alike, it also infringes on Pharoah’s bodily autonomy.”
But the strongest argument, Goldstein concluded, arching his eyebrow, is that “ever since I started speaking out on this issue, it’s been so easy to get with all the Midianite chicks at my school. That’s because they, like me, see past the endless intellectual arguments over ‘who started’ or ‘how’ or ‘why’ to the emotional truth that the suffering just has to stop, man.”
Last night, college towns across the Tigris, Euphrates, and Nile were aglow with candelight vigils for Baka Ahhotep, an Egyptian taskmaster and beloved father of three cruelly slain by “Genocide Moe,” in an altercation over alleged mistreatment of a Hebrew slave whose details remain disputed.
According to Caitlyn Mentuhotep, a sophomore majoring in hieroglyphic theory at the University of Pi-Ramesses who attended her school’s vigil for Ahhotep, staying true to her convictions hasn’t been easy in the face of Yahweh’s unending plagues—particularly the head lice. “But what keeps me going,” she said, “is the absolute certainty that, when people centuries from now write the story of our time, they’ll say that those of us who stood with Pharoah were on the right side of history.”
Update (April 19): Apparently a bug has been found, and the author has withdrawn the claim (see the comments).
For those who don’t yet know from their other social media: a week ago the cryptographer Yilei Chen posted a preprint, eprint.iacr.org/2024/555, claiming to give a polynomial-time quantum algorithm to solve lattice problems. For example, it claims to solve the GapSVP problem, which asks to approximate the length of the shortest nonzero vector in a given n-dimensional lattice, to within an approximation ratio of ~n4.5. The best approximation ratio previously known to be achievable in classical or quantum polynomial time was exponential in n.
If it’s correct, this is an extremely big deal. It doesn’t quite break the main lattice-based cryptosystems, but it would put those cryptosystems into a precarious position, vulnerable to a mere further polynomial improvement in the approximation factor. And, as we learned from the recent NIST competition, if the lattice-based and LWE-based systems were to fall, then we really don’t have many great candidates left for post-quantum public-key cryptography! On top of that, a full quantum break of LWE (which, again, Chen is not claiming) would lay waste (in a world with scalable QCs, of course) to a large fraction of the beautiful sandcastles that classical and quantum cryptographers have built up over the last couple decades—everything from Fully Homomorphic Encryption schemes, to Mahadev’s protocol for proving the output of any quantum computation to a classical skeptic.
So on the one hand, this would substantially enlarge the scope of exponential quantum speedups beyond what we knew a week ago: yet more reason to try to build scalable QCs! But on the other hand, it could also fuel an argument for coordinating to slow down the race to scalable fault-tolerant QCs, until the world can get its cryptographic house into better order. (Of course, as we’ve seen with the many proposals to slow down AI scaling, this might or might not be possible.)
So then, is the paper correct? I don’t know. It’s very obviously a serious effort by a serious researcher, a world away from the P=NP proofs that fill my inbox every day. But it might fail anyway. I’ve asked the world experts in quantum algorithms for lattice problems, and they’ve been looking at it, and none of them is ready yet to render a verdict. The central difficulty is that the algorithm is convoluted, and involves new tools that seem to come from left field, including complex Gaussian functions, the windowed quantum Fourier transform, and Karst waves (whatever those are). The algorithm has 9 phases by the author’s count. In my own perusal, I haven’t yet extracted even a high-level intuition—I can’t tell any little story like for Shor’s algorithm, e.g. “first you reduce factoring to period-finding, then you solve period-finding by applying a Fourier transform to a vector of amplitudes.”
So, the main purpose of this post is simply to throw things open to commenters! I’m happy to provide a public clearinghouse for questions and comments about the preprint, if those studying it would like that. You can even embed LaTeX in your comments, as will probably be needed to get anywhere.
Unrelated Update: Connor Tabarrok and his friends just put a podcast with me up on YouTube, in which they interview me in my office at UT Austin about watermarking of large language models and other AI safety measures.
Since the point of theoretical computer science is solely to recognize who is the most badass theoretical computer scientist, I can only say:
GO HOME PUNKS!
WIGDERSON OWNS YOU!
Avi Wigderson: central unifying figure of theoretical computer science for decades; consummate generalist who’s contributed to pretty much every corner of the field; advocate and cheerleader for the field; postdoc adviser to a large fraction of all theoretical computer scientists, including both me and my wife Dana; derandomizer of BPP (provided E requires exponential-size circuits). Now, Avi not only “owns you,” he also owns a well-deserved Turing Award (on top of his well-deserved Nevanlinna, Abel, Gödel, and Knuth prizes). As Avi’s health has been a matter of concern to those close to him ever since his cancer treatment, which he blogged about a few years ago, I’m sure today’s news will do much to lift his spirits.
I first met Avi a quarter-century ago, when I was 19, at a PCMI summer school on computational complexity at the Institute for Advanced Study in Princeton. Then I was lucky enough to visit Avi in Israel when he was still a professor at the Hebrew University (and I was a grad student at Berkeley)—first briefly, but then Avi invited me back to spend a whole semester in Jerusalem, which ended up being one of my most productive semesters ever. Then Avi, having by then moved to the IAS in Princeton, hosted me for a one-year postdoc there, and later he and I collaborated closely on the algebrization paper. He’s had a greater influence on my career than all but a tiny number of people, and I’m far from the only one who can say that.
Summarizing Avi’s scientific contributions could easily fill a book, but Quanta and New Scientist and Lance’s blog can all get you started if you’re interested. Eight years ago, I took a stab at explaining one tiny little slice of Avi’s impact—namely, his decades-long obsession with “why the permanent is so much harder than the determinant”—in my IAS lecture Avi Wigderson’s “Permanent” Impact On Me, to which I refer you now (I can’t produce a new such lecture on one day’s notice!).
Huge congratulations to Avi.
]]>17Scotthttp://www.scottaaronson.com<![CDATA[And yet quantum computing continues to progress]]>https://scottaaronson.blog/?p=79162024-04-05T03:35:47Z2024-04-03T17:28:59ZPissing away my life in a haze of doomscrolling, sporadic attempts to “parent” two rebellious kids, and now endless conversations about AI safety, I’m liable to forget for days that I’m still mostly known (such as I am) as a quantum computing theorist, and this blog is still mostly known as a quantum computing blog. Maybe it’s just that I spent a quarter-century on quantum computing theory. As an ADHD sufferer, anything could bore me after that much time, even one of the a-priori most exciting things in the world.
It’s like, some young whippersnappers proved another monster 80-page theorem that I’ll barely understand tying together the quantum PCP conjecture, area laws, and Gibbs states? Another company has a quantum software platform, or hardware platform, and they’ve issued a press release about it? Another hypester claimed that QC will revolutionize optimization and machine learning, based on the usual rogues’ gallery of quantum heuristic algorithms that don’t seem to outperform classical heuristics? Another skeptic claimed that scalable quantum computing is a pipe dream—mashing together the real reasons why it’s difficult with basic misunderstandings of the fault-tolerance theorem? In each case, I’ll agree with you that I probably should get up, sit at my laptop, and blog about it (it’s hard to blog with two thumbs), but as likely as not I won’t.
And yet quantum computing continues to progress. In December we saw Harvard and QuEra announce a small net gain from error-detection in neutral atoms, and accuracy that increased with the use of larger error-correcting codes. Today, a collaboration between Microsoft and Quantinuum has announced what might be the first demonstration of error-corrected two-qubit entangling gates with substantially lower error than the same gates applied to the bare physical qubits. (This is still at the stage where you need to be super-careful in how you phrase every such sentence—experts should chime in if I’ve already fallen short; I take responsibility for any failures to error-correct this post.)
You can read the research paper here, or I’ll tell you the details to the best of my understanding (I’m grateful to Microsoft’s Krysta Svore and others from the collaboration for briefing me by Zoom). The collaboration used a trapped-ion system with 32 fully-connected physical qubits (meaning, the qubits can be shuttled around a track so that any qubit can directly interact with any other). One can apply an entangling gate to any pair of qubits with ~99.8% fidelity.
What did they do with this system? They created up to 4 logical encoded qubits, using the Steane code and other CSS codes. Using logical CNOT gates, they then created logical Bell pairs — i.e., (|00⟩+|11⟩)/√2 — and verified that they did this.
That’s in the version of their experiment that uses “preselection but not postselection.” In other words, they have to try many times until they prepare the logical initial states correctly—as with magic state factories. But once they do successfully prepare the initial states, there’s no further cheating involving postselection (i.e., throwing away bad results): they just apply the logical CNOT gates, measure, and see what they got.
For me personally, that’s the headline result. But then they do various further experiments to “spike the football.” For one thing, they show that when they do allow postselected measurement outcomes, the decrease in the effective error rate can be much much larger, as large as 800x. That allows them (again, under postselection!) to demonstrate up to two rounds of error syndrome extraction and correction while still seeing a net gain, or three rounds albeit with unclear gain. The other thing they demonstrate is teleportation of fault-tolerant qubits—so, a little fancier than just preparing an encoded Bell pair and then measuring it.
They don’t try to do (e.g.) a quantum supremacy demonstration with their encoded qubits, like Harvard/QuEra did—they don’t have nearly enough qubits for that. But this is already extremely cool, and it sets a new bar in quantum error-correction experiments for others to meet or exceed (superconducting, neutral atom, and photonics people, that means you!). And I wasn’t expecting it! Indeed, I’m so far behind the times that I still imagined Microsoft as committed to a strategy of “topological qubits or bust.” While Microsoft is still pursuing the topological approach, their strategy has clearly pivoted over the last few years towards “whatever works.”
Anyway, huge congratulations to the teams at Microsoft and Quantinuum for their accomplishment!
Stepping back, what is the state of experimental quantum computing, 42 years after Feynman’s lecture, 30 years after Shor’s algorithm, 25 years after I entered the field, 5 years after Google’s supremacy experiment? There’s one narrative that quantum computing is already being used to solve practical problems that couldn’t be solved otherwise (look at all the hundreds of startups! they couldn’t possibly exist without providing real value, could they?). Then there’s another narrative that quantum computing has been exposed as a fraud, an impossibility, a pipe dream. Both narratives seem utterly disconnected from the reality on the ground.
If you want to track the experimental reality, my one-sentence piece of advice would be to focus relentlessly on the fidelity with which experimenters can apply a single physical 2-qubit gate. When I entered the field in the late 1990s, ~50% woud’ve been an impressive fidelity. At some point it became ~90%. With Google’s supremacy experiment in 2019, we saw 1000 gates applied to 53 qubits, each gate with ~99.5% fidelity. Now, in superconducting, trapped ions, and neutral atoms alike, we’re routinely seeing ~99.8% fidelities, which is what made possible (for example) the new Microsoft/Quantinuum result. The best fidelities I’ve heard reported this year are more like ~99.9%.
Meanwhile, on paper, it looks like known methods for quantum fault-tolerance, for example using the surface code, should start to become practical once you have 2-qubit fidelities around ~99.99%—i.e., one more “9” from where we are now. And then there should “merely” be the practical difficulty of maintaining that 99.99% fidelity while you scale up to millions or hundreds of millions of physical qubits!
What I’m trying to say is: this looks a pretty good trajectory! It looks like, if we plot the infidelity on a log scale, the experimentalists have already gone three-quarters of the distance. It now looks like it would be a surprise if we couldn’t have hundreds of fault-tolerant qubits and millions of gates on them within the next decade, if we really wanted that—like something unexpected would have to go wrong to prevent it.
Wouldn’t be ironic if all that was true, but it will simply matter much less than we hoped in the 1990s? Either just because the set of problems for which a quantum computing is useful has remained stubbornly more specialized than the world wants it to be (for more on that, see the entire past 20 years of this blog) … or because advances in classical AI render what was always quantum computing’s most important killer app, to the simulation of quantum chemistry and materials, increasingly superfluous (as AlphaFold may have already done for protein folding) … or simply because civilization descends further into barbarism, or the unaligned AGIs start taking over, and we all have bigger things to worry about than fault-tolerant quantum computing.
But, you know, maybe fault-tolerant quantum computing will not only work, but matter—and its use to design better batteries and drugs and photovoltaic cells and so on will pass from science-fiction fantasy to quotidian reality so quickly that much of the world (weary from the hypesters crying wolf too many times?) will barely even notice it when it finally happens, just like what we saw with Large Language Models a few years ago. That would be worth getting out of bed for.
]]>143Scotthttp://www.scottaaronson.com<![CDATA[Open Letter to Anti-Zionists on Twitter]]>https://scottaaronson.blog/?p=78452024-04-03T15:04:17Z2024-03-25T05:53:36ZDear Twitter Anti-Zionists,
For five months, ever since Oct. 7, I’ve read you obsessively. While my current job is supposed to involve protecting humanity from the dangers of AI (with a side of quantum computing theory), I’m ashamed to say that half the days I don’t do any science; instead I just scroll and scroll, reading anti-Israel content and then pro-Israel content and then more anti-Israel content. I thought refusing to post on Twitter would save me from wasting my life there as so many others have, but apparently it doesn’t, not anymore. (No, I won’t call it “X.”)
At the high end of the spectrum, I religiously check the tweets of Paul Graham, a personal hero and inspiration to me ever since he wrote Why Nerds Are Unpopular twenty years ago, and a man with whom I seem to resonate deeply on every important topic except for two: Zionism and functional programming. At the low end, I’ve read hundreds of the seemingly infinite army of Tweeters who post images of hook-nosed rats with black hats and sidecurls and dollar signs in their eyes, sneering as they strangle the earth and stab Palestinian babies. I study their detailed theories about why the October 7 pogrom never happened, and also it was secretly masterminded by Israel just to create an excuse to mass-murder Palestinians, and also it was justified and thrilling (exactly the same melange long ago embraced for the Holocaust).
I’m aware, of course, that the bottom-feeders make life too easy for me, and that a single Paul Graham who endorses the anti-Zionist cause ought to bother me more than a billion sharers of hook-nosed rat memes. And he does. That’s why, in this letter, I’ll try to stay at the higher levels of Graham’s Disagreement Hierarchy.
More to the point, though, why have I spent so much time on such a depressing, unproductive reading project?
Damned if I know. But it’s less surprising when you recall that, outside theoretical computer science, I’m (alas) mostly known to the world for having once confessed, in a discussion deep in the comment section of this blog, that I spent much of my youth obsessively studying radical feminist literature. I explained that I did that because my wish, for a decade, was to confront progressivism’s highest moral authorities on sex and relationships, and make them tell me either that
(1) I, personally, deserved to die celibate and unloved, as a gross white male semi-autistic STEM nerd and stunted emotional and aesthetic cripple, or else (2) no, I was a decent human being who didn’t deserve that.
One way or the other, I sought a truthful answer, one that emerged organically from the reigning morality of our time and that wasn’t just an unprincipled exception to it. And I felt ready to pursue progressive journalists and activists and bloggers and humanities professors to the ends of the earth before I’d let them leave this one question hanging menacingly over everything they’d ever written, with (I thought) my only shot at happiness in life hinging on their answer to it.
You might call this my central character flaw: this need for clarity from others about the moral foundations of my own existence. I’m self-aware enough to know that it is a severe flaw, but alas, that doesn’t mean that I ever figured out how to fix it.
It’s been exactly the same way with the anti-Zionists since October 7. Every day I read them, searching for one thing and one thing only: their own answer to the “Jewish Question.” How would they ensure that the significant fraction of the world that yearns to murder all Jews doesn’t get its wish in the 21st century, as to a staggering extent it did in the 20th? I confess to caring about that question, partly (of course) because of the accident of having been born a Jew, and having an Israeli wife and family in Israel and so forth, but also because, even if I’d happened to be a Gentile, the continued survival of the world’s Jews would still seem remarkably bound up with science, Enlightenment, minority rights, liberal democracy, meritocracy, and everything else I’ve ever cared about.
I understand the charges against me. Namely: that if I don’t call for Israel to lay down its arms right now in its war against Hamas (and ideally: to dissolve itself entirely), then I’m a genocidal monster on the wrong side of history. That I value Jewish lives more than Palestinian lives. That I’m a hasbara apologist for the IDF’s mass-murder and apartheid and stealing of land. That if images of children in Gaza with their limbs blown off, or dead in their parents arms, or clawing for bread, don’t cause to admit that Israel is evil, then I’m just as evil as the Israelis are.
Unsurprisingly I contest the charges. As a father of two, I can no longer see any images of child suffering without thinking about my own kids. For all my supposed psychological abnormality, the part of me that’s horrified by such images seems to be in working order. If you want to change my mind, rather than showing me more such images, you’ll need to target the cognitive part of me: the part that asks why so many children are suffering, and what causal levers we’d need to push to reach a place where neither side’s children ever have to suffer like this ever again.
At risk of stating the obvious: my first-order model is that Hamas, with the diabolical brilliance of a Marvel villain, successfully contrived a situation where Israel could prevent the further massacring of its own population only by fighting a gruesome urban war, of a kind that always, anywhere in the world, kills tens of thousands of civilians. Hamas, of course, was helped in this plan by an ideology that considers martyrdom the highest possible calling for the innocents who it rules ruthlessly and hides underneath. But Hamas also understood that the images of civilian carnage would (rightly!) shock the consciences of Israel’s Western allies and many Israelis themselves, thereby forcing a ceasefire before the war was over, thereby giving Hamas the opportunity to regroup and, with God’s and of course Iran’s help, finally finish the job of killing all Jews another day.
And this is key: once you remember why Hamas launched this war and what its long-term goals are, every detail of Twitter’s case against Israel has to be reexamined in a new light. Take starvation, for example. Clearly the only explanation for why Israelis would let Gazan children starve is the malice in their hearts? Well, until you think through the logistical challenges of feeding 2.3 million starving people whose sole governing authority is interested only in painting the streets red with Jewish blood. Should we let that authority commandeer the flour and water for its fighters, while innocents continue to starve? No? Then how about UNRWA? Alas, we learned that UNRWA, packed with employees who cheered the Oct. 7 massacre in their Telegram channels and in some cases took part in the murders themselves, capitulates to Hamas so quickly that it effectively is Hamas. So then Israel should distribute the food itself! But as we’ve dramatically witnessed, Israel can’t distribute food without imposing order, which would seem to mean reoccupying Gaza and earning the world’s condemnation for it. Do you start to appreciate the difficulty of the problem—and why the Biden administration was pushed to absurd-sounding extremes like air-dropping food and then building a floating port?
It all seems so much easier, once you remove the constraint of not empowering Hamas in its openly-announced goal of completing the Holocaust. And hence, removing that constraint is precisely what the global left does.
For all that, by Israeli standards I’m firmly in the anti-Netanyahu, left-wing peace camp—exactly where I’ve been since the 1990s, as a teenager mourning the murder of Rabin. And I hope even the anti-Israel side might agree with me that, if all the suffering since Oct. 7 has created a tiny opening for peace, then walking through that opening depends on two things happening:
the removal of Netanyahu, and
the removal of Hamas.
The good news is that Netanyahu, the catastrophically failed “Protector of Israel,” not only can, but plausibly will (if enough government ministers show some backbone), soon be removed in a democratic election.
Hamas, by contrast, hasn’t allowed a single election since it took power in 2006, in a process notable for its opponents being thrown from the roofs of tall buildings. That’s why even my left-leaning Israeli colleagues—the ones who despise Netanyahu, who marched against him last year—support Israel’s current war. They support it because, even if the Israeli PM were Fred Rogers, how can you ever get to peace without removing Hamas, and how can you remove Hamas except by war, any more than you could cut a deal with Nazi Germany?
I want to see the IDF do more to protect Gazan civilians—despite my bitter awareness of survey data suggesting that many of those civilians would murder my children in front of me if they ever got a chance. Maybe I’d be the same way if I’d been marinated since birth in an ideology of Jew-killing, and blocked from other sources of information. I’m heartened by the fact that despite this, indeed despite the risk to their lives for speaking out, a full 15% of Gazans openly disapprove of the Oct. 7 massacre. I want a solution where that 15% becomes 95% with the passing of generations. My endgame is peaceful coexistence.
But to the anti-Zionists I say: I don’t even mind you calling me a baby-eating monster, provided you honestly field one question. Namely:
Suppose the Palestinian side got everything you wanted for it; then what would be your plan for the survival of Israel’s Jews?
Let’s assume that not only has Netanyahu lost the next election in a landslide, but is justly spending the rest of his life in Israeli prison. Waving my wand, I’ve made you Prime Minister in his stead, with an overwhelming majority in the Knesset. You now get to go down in history as the liberator of Palestine. But you’re now also in charge of protecting Israel’s 7 million Jews (and 2 million other residents) from near-immediate slaughter at the hands of those who you’ve liberated.
Granted, it seems pretty paranoid to expect such a slaughter! Or rather: it would seem paranoid, if the Palestinians’ Grand Mufti (progenitor of the Muslim Brotherhood and hence Hamas) hadn’t allied himself with Hitler in WWII, enthusiastically supported the Nazi Final Solution, and tried to export it to Palestine; if in 1947 the Palestinians hadn’t rejected the UN’s two-state solution (the one Israel agreed to) and instead launched another war to exterminate the Jews (a war they lost); if they hadn’t joined the quest to exterminate the Jews a third time in 1967; etc., or if all this hadn’t happened back before there were any settlements or occupation, when the only question on the table was Israel’s existence. It would seem paranoid if Arafat had chosen a two-state solution when Israel offered it to him at Camp David, rather than suicide bombings. It would seem paranoid if not for the candies passed out in the streets in celebration on October 7.
But if someone has a whole ideology, which they teach their children and from which they’ve never really wavered for a century, about how murdering you is a religious honor, and also they’ve actually tried to murder you at every opportunity—-what more do you want them to do, before you’ll believe them?
So, you tell me your plan for how to protect Israel’s 7 million Jews from extermination at the hands of neighbors who have their extermination—my family’s extermination—as their central political goal, and who had that as their goal long before there was any occupation of the West Bank or Gaza. Tell me how to do it while protecting Palestinian innocents. And tell me your fallback plan if your first plan turns out not to work.
We can go through the main options.
(1) UNILATERAL TWO-STATE SOLUTION
Maybe your plan is that Israel should unilaterally dismantle West Bank settlements, recognize a Palestinian state, and retreat to the 1967 borders.
This is an honorable plan. It was my preferred plan—until the horror of October 7, and then the even greater horror of the worldwide left reacting to that horror by sharing celebratory images of paragliders, and by tearing down posters of kidnapped Jewish children.
Today, you might say October 7 has sort of put a giant flaming-red exclamation point on what’s always been the central risk of unilateral withdrawal. Namely: what happens if, afterward, rather than building a peaceful state on their side of the border, the Palestinian leadership chooses instead to launch a new Iran-backed war on Israel—one that, given the West Bank’s proximity to Israel’s main population centers, makes October 7 look like a pillow fight?
If that happens, will you admit that the hated Zionists were right and you were wrong all along, that this was never about settlements but always, only about Israel’s existence? Will you then agree that Israel has a moral prerogative to invade the West Bank, to occupy and pacify it as the Allies did Germany and Japan after World War II? Can I get this in writing from you, right now? Or, following the future (October 7)2 launched from a Judenfrei West Bank, will your creativity once again set to work constructing a reason to blame Israel for its own invasion—because you never actually wanted a two-state solution at all, but only Israel’s dismantlement?
(2) NEGOTIATED TWO-STATE SOLUTION
So, what about a two-state solution negotiated between the parties? Israel would uproot all West Bank settlements that prevent a Palestinian state, and resettle half a million Jews in pre-1967 Israel—in exchange for the Palestinians renouncing their goal of ending Israel’s existence, via a “right of return” or any other euphemism.
If so: congratulations, your “anti-Zionism” now seems barely distinguishable from my “Zionism”! If they made me the Prime Minister of Israel, and put you in charge of the Palestinians, I feel optimistic that you and I could reach a deal in an hour and then go out for hummus and babaganoush.
(3) SECULAR BINATIONAL STATE
In my experience, in the rare cases they deign to address the question directly, most anti-Zionists advocate a “secular, binational state” between the Jordan and Mediterranean, with equal rights for all inhabitants. Certainly, that would make sense if you believe that Israel is an apartheid state just like South Africa.
To me, though, this analogy falls apart on a single question: who’s the Palestinian Nelson Mandela? Who’s the Palestinian leader who’s ever said to the Jews, “end your Jewish state so that we can live together in peace,” rather than “end your Jewish state so that we can end your existence”? To impose a binational state would be to impose something, not only that Israelis regard as an existential horror, but that most Palestinians have never wanted either.
But, suppose we do it anyway. We place 7 million Jews, almost half the Jews who remain on Earth, into a binational state where perhaps a third of their fellow citizens hold the theological belief that all Jews should be exterminated, and that a heavenly reward follows martyrdom in blowing up Jews. The exterminationists don’t quite have a majority, but they’re the second-largest voting bloc. Do you predict that the exterminationists will give up their genocidal ambition because of new political circumstances that finally put their ambition within reach? If October-7 style pogroms against Jews turn out to be a regular occurrence in our secular binational state, how will its government respond—like the Palestinian Authority? like UNRWA? like the British Mandate? like Tsarist Russia?
In such a case, perhaps the Jews (along with those Arabs and Bedouins and Druze and others who cast their lot with the Jews) would need form a country-within-a-country: their own little autonomous zone within the binational state, with its own defense force. But of course, such a country-within-a-country already formed, for pretty much this exact reason. It’s called Israel. A cycle has been detected in your arc of progress.
(4) EVACUATION OF THE JEWS FROM ISRAEL
We come now to the anti-Zionists who are plainspoken enough to say: Israel’s creation was a grave mistake, and that mistake must now be reversed.
This is a natural option for anyone who sees Israel as an “illegitimate settler-colonial project,” like British India or French Algeria, but who isn’t quite ready to call for another Jewish genocide.
Again, the analogy runs into obvious problems: Israelis would seem to be the first “settler-colonialists” in the history of the world who not only were indigenous to the land they colonized, as much as anyone was, but who weren’t colonizing on behalf of any mother country, and who have no obvious such country to which they can return.
Some say spitefully: then let the Jews go back to Poland. These people might be unaware that, precisely because of how thorough the Holocaust was, more Israeli Jews trace their ancestry to Muslim countries than to Europe. Is there to be a “right of return” to Egypt, Iraq, Morocco, and Yemen, for all the Jews forcibly expelled from those places and for their children and grandchildren?
Others, however, talk about evacuating the Jews from Israel with goodness in their hearts. They say: we’d love the Israelis’ economic dynamism here in Austin or Sydney or Oxfordshire, joining their many coreligionists who already call these places home. What’s more, they’ll be safer here—who wants to live with missiles raining down on their neighborhood? Maybe we could even set aside some acres in Montana for a new Jewish homeland.
Again, if this is your survival plan, I’m a billion times happier to discuss it openly than to have it as unstated subtext!
Except, maybe you could say a little more about the logistics. Who will finance the move? How confident are you that the target country will accept millions of defeated, desperate Jews, as no country on earth was the last time this question arose?
I realize it’s no longer the 1930s, and Israel now has friends, most famously in America. But—what’s a good analogy here? I’ve met various Silicon Valley gazillionaires. I expect that I could raise millions from them, right now, if I got them excited about a new project in quantum computing or AI or whatever. But I doubt I could raise a penny from them if I came to them begging for their pity or their charity.
Likewise: for all the anti-Zionists’ loudness, a solid majority of Americans continue to support Israel (which, incidentally, provides a much simpler explanation than the hook-nosed perfidy of AIPAC for why Congress and the President mostly support it). But it seems to me that Americans support Israel in the “exciting project” sense, rather than in the “charity” sense. They like that Israelis are plucky underdogs who made the deserts bloom, and built a thriving tech industry, and now produce hit shows like Shtisel and Fauda, and take the fight against a common foe to the latter’s doorstep, and maintain one of the birthplaces of Western civilization for tourists and Christian pilgrims, and restarted the riveting drama of the Bible after a 2000-year hiatus, which some believe is a crucial prerequisite to the Second Coming.
What’s important, for present purposes, is not whether you agree with any of these rationales, but simply that none of them translate into a reason to accept millions of Jewish refugees.
But if you think dismantling Israel and relocating its seven million Jews is a workable plan—OK then, are you doing anything to make that more than a thought experiment, as the Zionists did a century ago with their survival plan? Have even I done more to implement your plan than you have, by causing one Israeli (my wife) to move to the US?
Suppose you say it’s not your job to give me a survival plan for Israel’s Jews. Suppose you say the request is offensive, an attempt to distract from the suffering of the Palestinians, so you change the subject.
In that case, fine, but you can now take off your cloak of righteousness, your pretense of standing above me and judging me from the end of history. Your refusal to answer the question amounts to a confession that, for you, the goal of “a free Palestine from the river to the sea” doesn’t actually require the physical survival of Israel’s Jews.
Which means, we’ve now established what you are. I won’t give you the satisfaction of calling you a Nazi or an antisemite. Thousands of years before those concepts existed, Jews already had terms for you. The terms tended toward a liturgical register, as in “those who rise up in every generation to destroy us.” The whole point of all the best-known Jewish holidays, like Purim yesterday, is to talk about those wicked would-be destroyers in the past tense, with the very presence of live Jews attesting to what the outcome was.
(Yesterday, I took my kids to a Purim carnival in Austin. Unlike in previous years, there were armed police everywhere. It felt almost like … visiting Israel.)
If you won’t answer the question, then it wasn’t Zionist Jews who told you that their choices are either to (1) oppose you or else (2) go up in black smoke like their grandparents did. You just told them that yourself.
Many will ask: why don’t I likewise have an obligation to give you my Palestinian survival plan?
I do. But the nice thing about my position is that I can tell you my Palestinian survival plan cheerfully, immediately, with zero equivocating or changing the subject. It’s broadly the same plan that David Ben-Gurion and Yitzchak Rabin and Ehud Barak and Bill Clinton and the UN put on the table over and over and over, only for the Palestinians’ leaders to sweep it off.
I want the Palestinians to have a state, comprising the West Bank and Gaza, with a capital in East Jerusalem. I want Israel to uproot all West Bank settlements that prevent such a state. I want this to happen the instant there arises a Palestinian leadership genuinely committed to peace—one that embraces liberal values and rejects martyr values, in everything from textbooks to street names.
And I want more. I want the new Palestinian state to be as prosperous and free and educated as modern Germany and Japan are. I want it to embrace women’s rights and LGBTQ+ rights and the rest of the modern package, so that “Queers for Palestine” would no longer be a sick joke. I want the new Palestine to be as intertwined with Israel, culturally and economically, as the US and Canada are.
Ironically, if this ever became a reality, then Israel-as-a-Jewish-state would no longer be needed—but it’s certainly needed in the meantime.
Anti-Zionists on Twitter: can you be equally explicit about what you want?
I come, finally, to what many anti-Zionists regard as their ultimate trump card. Look at all the anti-Zionist Jews and Israelis who agree with us, they say. Jewish Voice for Peace. IfNotNow. Noam Chomsky. Norman Finkelstein. The Neturei Karta.
Intellectually, of course, the fact of anti-Zionist Jews makes not the slightest difference to anything. My question for them remains exactly the same as for anti-Zionist Gentiles: what is your Jewish survival plan, for the day after we dismantle the racist supremacist apartheid state that’s currently the only thing standing between half the world’s remaining Jews and their slaughter by their neighbors? Feel free to choose from any of the four options above, or suggest a fifth.
But in the event that Jewish anti-Zionists evade that conversation, or change the subject from it, maybe some special words are in order. You know the famous Golda Meir line, “If we have to choose between being dead and pitied and being alive with a bad image, we’d rather be alive and have the bad image”?
It seems to me that many anti-Zionist Jews considered Golda Meir’s question carefully and honestly, and simply decided it the other way, in favor of Jews being dead and pitied.
Bear with me here: I won’t treat this as a reductio ad absurdum of their position. Not even if the anti-Zionist Jews themselves wish to remain safely ensconced in Berkeley or New Haven, while the Israelis fulfill the “dead and pitied” part for them.
In fact, I’ll go further. Again and again in life I’ve been seized by a dark thought: if half the world’s Jews can only be kept alive, today, via a militarized ethnostate that constantly needs to defend its existence with machine guns and missiles, racking up civilian deaths and destabilizing the world’s geopolitics—if, to put a fine point on it, there are 16 million Jews in the world, but at least a half billion antisemites who wake up every morning and go to sleep every night desperately wishing those Jews dead—then, from a crude utilitarian standpoint, might it not be better for the world if we Jews vanished after all?
Remember, I’m someone who spent a decade asking myself whether the rapacious, predatory nature of men’s sexual desire for women, which I experienced as a curse and an affliction, meant that the only moral course for me was to spend my life as a celibate mathematical monk. But I kept stumbling over one point: why should such a moral obligation fall on me alone? Why doesn’t it fall on other straight men, particularly the ones who presume to lecture me on my failings?
And also: supposing I did take the celibate monk route, would even that satisfy my haters? Would they come after me anyway for glancing at a woman too long or making an inappropriate joke? And also: would the haters soon say I shouldn’t have my scientific career either, since I’ve stolen my coveted academic position from the underprivileged? Where exactly does my self-sacrifice end?
When I did, finally, start approaching women and asking them out on dates, I worked up the courage partly by telling myself: I am now going to do the Zionist thing. I said: if other nerdy Jews can risk death in war, then this nerdy Jew can risk ridicule and contemptuous stares. You can accept that half the world will denounce you as a monster for living your life, so long as your own conscience (and, hopefully, the people you respect the most) continue to assure you that you’re nothing of the kind.
This took more than a decade of internal struggle, but it’s where I ended up. And today, if anyone tells me I had no business ever forming any romantic attachments, I have two beautiful children as my reply. I can say: forget about me, you’re asking for my children never to have existed—that’s why I’m confident you’re wrong.
Likewise with the anti-Zionists. When the Twitter-warriors share their memes of hook-nosed Jews strangling the planet, innocent Palestinian blood dripping from their knives, when the global protests shut down schools and universities and bridges and parliament buildings, there’s a part of me that feels eager to commit suicide if only it would appease the mob, if only it would expiate all the cosmic guilt they’ve loaded onto my shoulders.
But then I remember that this isn’t just about me. It’s about Einstein and Spinoza and Feynman and Erdös and von Neumann and Weinberg and Landau and Michelson and Rabi and Tarski and Asimov and Sagan and Salk and Noether and Meitner, and Irving Berlin and Stan Lee and Rodney Dangerfield and Steven Spielberg. Even if I didn’t happen to be born Jewish—if I had anything like my current values, I’d still think that so much of what’s worth preserving in human civilization, so much of math and science and Enlightenment and democracy and humor, would seem oddly bound up with the continued survival of this tiny people. And conversely, I’d think that so much of what’s hateful in civilization would seem oddly bound up with the quest to exterminate this tiny people, or to deny it any means to defend itself from extermination.
So that’s my answer, both to anti-Zionist Gentiles and to anti-Zionist Jews. The problem of Jewish survival, on a planet much of which yearns for the Jews’ annihilation and much of the rest of which is indifferent, is both hard and important, like P versus NP. And so a radical solution was called for. The solution arrived at a century ago, at once brand-new and older than Homer and Hesiod, was called the State of Israel. If you can’t stomach that solution—if, in particular, you can’t stomach the violence needed to preserve it, so long as Israel’s neighbors retain their annihilationist dream—then your response ought to be to propose a better solution. I promise to consider your solution in good faith—asking, just like with P vs. NP provers, how you overcome the problems that doomed all previous attempts. But if you throw my demand for a better solution back in my face, then you might as well be pushing my kids into a gas chamber yourself, for all the moral authority that I now recognize you to have over me.
Possibly the last thing Einstein wrote was a speech celebrating Israel’s 7th Independence Day, which he died a week before he was to deliver. So let’s turn the floor over to Mr. Albert, the leftist pacifist internationalist:
This is the seventh anniversary of the establishment of the State of Israel. The establishment of this State was internationally approved and recognised largely for the purpose of rescuing the remnant of the Jewish people from unspeakable horrors of persecution and oppression.
Thus, the establishment of Israel is an event which actively engages the conscience of this generation. It is, therefore, a bitter paradox to find that a State which was destined to be a shelter for a martyred people is itself threatened by grave dangers to its own security. The universal conscience cannot be indifferent to such peril.
It is anomalous that world opinion should only criticize Israel’s response to hostility and should not actively seek to bring an end to the Arab hostility which is the root cause of the tension.
I love Einstein’s use of “anomalous,” as if this were a physics problem. From the standpoint of history, what’s anomalous about the Israeli-Palestinian conflict is not, as the Twitterers claim, the brutality of the Israelis—if you think that’s anomalous, you really haven’t studied history—but something different. In other times and places, an entity like Palestine, which launches a war of total annihilation against a much stronger neighbor, and then another and another, would soon disappear from the annals of history. Israel, however, is held to a different standard. Again and again, bowing to international pressure and pressure from its own left flank, the Israelis have let their would-be exterminators off the hook, bruised but mostly still alive and completely unrepentant, to have another go at finishing the Holocaust in a few years. And after every bout, sadly but understandably, Israeli culture drifts more to the right, becomes 10% more like the other side always was.
I don’t want Israel to drift to the right. I find the values of Theodor Herzl and David Ben-Gurion to be almost as good as any human values have ever been, and I’d like Israel to keep them. Of course, Israel will need to continue defending itself from genocidal neighbors, until the day that a leader arises among the Palestinians with the moral courage of Egypt’s Anwar Sadat or Jordan’s King Hussein: a leader who not only talks peace but means it. Then there can be peace, and an end of settlements in the West Bank, and an independent Palestinian state. And however much like dark comedy that seems right now, I’m actually optimistic that it will someday happen, conceivably even soon depending on what happens in the current war. Unless nuclear war or climate change or AI apocalypse makes the whole question moot.
Anyway, thanks for reading—a lot built up these past months that I needed to get off my chest. When I told a friend that I was working on this post, he replied “I agree with you about Israel, of course, but I choose not to die on that hill in public.” I answered that I’ve already died on that hill and on several other hills, yet am somehow still alive!
Meanwhile, I was gratified that other friends, even ones who strongly disagree with me about Israel, told me that I should not disengage, but continue to tell it like I see it, trying civilly to change minds while being open to having my own mind changed.
And now, maybe, I can at last go back to happier topics, like how to prevent the destruction of the world by AI.
Cheers, Scott
]]>255Scotthttp://www.scottaaronson.com<![CDATA[Never go to “Planet Word” in Washington DC]]>https://scottaaronson.blog/?p=78862024-03-15T21:09:07Z2024-03-15T20:49:37ZIn fact, don’t try to take kids to Washington DC if you can possibly avoid it.
This is my public service announcement. This is the value I feel I can add to the world today.
Dana and I decided to take the kids to DC for spring break. The trip, alas, has been hell—a constant struggle against logistical failures. The first days were mostly spent sitting in traffic or searching for phantom parking spaces that didn’t exist. (So then we switched to the Metro, and promptly got lost, and had our metro cards rejected by the machines.) Or, at crowded cafes, I spent the time searching for a table so my starving kids could eat—and then when I finally found a table, a woman, smug and sure-faced, evicted us from the table because she was “going to” sit there, and my kids had to see that their dad could not provide for their basic needs, and that woman will never face any consequence for what she did.
Anyway, this afternoon, utterly frazzled and stressed and defeated, we entered “Planet Word,” a museum about language. Sounds pretty good, right? Except my soon-to-be 7-year-old son got bored by numerous exhibits that weren’t for him. So I told him he could lead the way and find any exhibit he liked.
Finally my son found an exhibit that fascinated him, one where he could weigh plastic fruits on a balancing scale. He was engrossed by it, he was learning, he was asking questions, I reflected that maybe the trip wasn’t a total loss … and that’s when a museum employee pointed at us, and screamed at us to leave the room, because “this exhibit was sold out.”
The room was actually almost empty (!). No one had stopped us from entering the room. No one else was waiting to use the balancing scale. There was no sign to warn us we were doing anything wrong. I would’ve paid them hundreds of dollars in that moment if only we could stay. My son didn’t understand why he was suddenly treated as a delinquent. He then wanted to leave the whole museum, and so did I. The day was ruined for us.
Mustering my courage to do something uncharacteristic for me, I complained at the front desk. They sneered and snickered at me, basically told me to go to hell. Looking deeply into their dumb, blank expressions, I realized that I had as much chance of any comprehension or sympathy as I’d have from a warthog. It’s true that, on the scale of all the injustices in the history of the world, this one surely didn’t crack the top quadrillion. But for me, in that moment, it came to stand for all the others. Which has always been my main weakness as a person, that injustice affects me in that way.
Speaking of which, there was one part of DC trip that went exactly like it was supposed to. That was our visit to the United States Holocaust Memorial Museum. Why? Because I feel like that museum, unlike all the rest, tells me the truth about the nature of the world that I was born into—and seeing the truth is perversely comforting. I was born into a world that right now, every day, is filled with protesters screaming for my death, for my family’s death—and this is accepted as normal, and those protesters sleep soundly at night, congratulating themselves for their progressivism and enlightenment. And thinking about those protesters, and their predecessors 80 years ago who perpetrated the Holocaust or who stood by and let it happen, is the only thing that really puts blankfaced museum employees into perspective for me. Like, of course a world with the former is also going to have the latter—and I should count myself immeasurably lucky if the latter is all I have to deal with, if the empty-skulled and the soul-dead can only ruin my vacation and lack the power to murder my family.
And to anyone who reached the end of this post and who feels like it was an unwelcome imposition on their time: I’m sorry. But the truth is, posts like this are why I started this blog and why I continue it. If I’ve ever imparted any interesting information or ideas, that’s a byproduct that I’m thrilled about. But I’m cursed to be someone who wakes up every morning, walks around every day, and goes to sleep every night crushed by the weight of the world’s injustice, and outside of technical subjects, the only thing that’s ever motivated me to write is that words are the only justice available to me.
]]>68Scotthttp://www.scottaaronson.com<![CDATA[On being faceless]]>https://scottaaronson.blog/?p=78702024-03-06T18:29:48Z2024-03-06T14:29:13ZUpdate: Alright, I’m back in. (After trying the same recovery mechanisms that didn’t work before, but suddenly did work this afternoon.) Thanks also to the Facebook employee who emailed offering to help. Now I just need to decide the harder question of whether I want to be back in!
So I’ve been locked out of Facebook and Messenger, possibly forever. It started yesterday morning, when Facebook went down for the entire world. Now it’s back up for most people, but I can’t get in—neither with passwords (none of which work), nor with text messages to my phone (my phone doesn’t receive them for some reason). As a last-ditch measure, I submitted my driver’s license into a Facebook black hole from which I don’t expect to hear back.
Incidentally, this sort of thing is why, 25 years ago, I became a theoretical rather than applied computer scientist. Even before you get to any serious software engineering, the applied part of computing involves a neverending struggle to make machines do what you need them to do—get a document to print, a website to load, a software package to install—in ways that are harrowing and not the slightest bit intellectually interesting. You learn, not about the nature of reality, but only about the terrible design decisions of other people. I might as well be a 90-year-old grandpa with such things, and if I didn’t have the excuse of being a theorist, that fact would constantly humiliate me before my colleagues.
Anyway, maybe some Facebook employee will see this post and decide to let me back in. Otherwise, it feels like a large part of my life has been cut away forever—but maybe that’s good, like cutting away a malignant tumor. Maybe, even if I am let back in, I should refrain from returning, or at least severely limit the time I spend there.
The truth is that, over the past eight years or so, I let more and more of my online activity shift from this blog to Facebook. Partly that’s because (as many others have lamented) the Golden Age of Blogs came to an end, with intellectual exploration and good-faith debate replaced by trolling, sniping, impersonation, and constant attempts to dox opponents and ruin their lives. As a result, more and more ideas for new blog posts stayed in my drafts folder—they always needed just one more revision to fortify them against inevitable attack, and then that one more revision never happened. It was simply more comfortable to post my ideas on Facebook, where the feedback came from friends and colleagues using their real names, and where any mistakes I made would be contained. But, on the reflection that comes from being locked out, maybe Facebook was simply a trap. What I have neither the intellectual courage to say in public, nor the occasion to say over dinner with real-life friends and family and colleagues, maybe I should teach myself not to say at all.
]]>35Scotthttp://www.scottaaronson.com<![CDATA[The Problem of Human Specialness in the Age of AI]]>https://scottaaronson.blog/?p=77842024-03-08T21:21:09Z2024-02-12T16:08:17ZUpdate (Feb. 29): A YouTube video of this talk is now available, plus a comment section filled (as usual) with complaints about everything from my speech and mannerisms to my failure to address the commenter’s pet topic.
Another Update (March 8):YouTube video of a shorter (18-minute) version of this talk, which I delivered at TEDxPaloAlto, is now available as well!
Here, as promised in my last post, is a written version of the talk I delivered a couple weeks ago at MindFest in Florida, entitled “The Problem of Human Specialness in the Age of AI.” The talk is designed as one-stop shopping, summarizing many different AI-related thoughts I’ve had over the past couple years (and earlier).
1. INTRO
Thanks so much for inviting me! I’m not an expert in AI, let alone mind or consciousness. Then again, who is?
For the past year and a half, I’ve been moonlighting at OpenAI, thinking about what theoretical computer science can do for AI safety. I wanted to share some thoughts, partly inspired by my work at OpenAI but partly just things I’ve been wondering about for 20 years. These thoughts are not directly about “how do we prevent super-AIs from killing all humans and converting the galaxy into paperclip factories?”, nor are they about “how do we stop current AIs from generating misinformation and being biased?,” as much attention as both of those questions deserve (and are now getting). In addition to “how do we stop AGI from going disastrously wrong?,” I find myself asking “what if it goes right? What if it just continues helping us with various mental tasks, but improves to where it can do just about any task as well as we can do it, or better? Is there anything special about humans in the resulting world? What are we still for?”
2. LARGE LANGUAGE MODELS
I don’t need to belabor for this audience what’s been happening lately in AI. It’s arguably the most consequential thing that’s happened in civilization in the past few years, even if that fact was temporarily masked by various ephemera … y’know, wars, an insurrection, a global pandemic … whatever, what about AI?
I assume you’ve all spent time with ChatGPT, or with Bard or Claude or other Large Language Models, as well as with image models like DALL-E and Midjourney. For all their current limitations—and we can discuss the limitations—in some ways these are the thing that was envisioned by generations of science fiction writers and philosophers. You can talk to them, and they give you a comprehending answer. Ask them to draw something and they draw it.
I think that, as late as 2019, very few of us expected this to exist by now. I certainly didn’t expect it to. Back in 2014, when there was a huge fuss about some silly ELIZA-like chatbot called “Eugene Goostman” that was falsely claimed to pass the Turing Test, I asked around: why hasn’t anyone tried to build a much better chatbot, by (let’s say) training a neural network on all the text on the Internet? But of course I didn’t do that, nor did I know what would happen when it was done.
The surprise, with LLMs, is not merely that they exist, but the way they were created. Back in 1999, you would’ve been laughed out of the room if you’d said that all the ideas needed to build an AI that converses with you in English already existed, and that they’re basically just neural nets, backpropagation, and gradient descent. (With one small exception, a particular architecture for neural nets called the transformer, but that probably just saves you a few years of scaling anyway.) Ilya Sutskever, cofounder of OpenAI (who you might’ve seen something about in the news…), likes to say that beyond those simple ideas, you only needed three ingredients:
(1) a massive investment of computing power, (2) a massive investment of training data, and (3) faith that your investments would pay off!
Crucially, and even before you do any reinforcement learning, GPT-4 clearly seems “smarter” than GPT-3, which seems “smarter” than GPT-2 … even as the biggest ways they differ are just the scale of compute and the scale of training data! Like,
GPT-2 struggled with grade school math.
GPT-3.5 can do most grade school math but it struggles with undergrad material.
GPT-4, right now, can probably pass most undergraduate math and science classes at top universities (I mean, the ones without labs or whatever!), and possibly the humanities classes too (those might even be easier for GPT-4 than the science classes, but I’m much less confident about it). But it still struggles with, for example, the International Math Olympiad. How insane, that this is now where we have to place the bar!
Obvious question: how far will this sequence continue? There are certainly a least a few more orders of magnitude of compute before energy costs become prohibitive, and a few more orders of magnitude of training data before we run out of public Internet. Beyond that, it’s likely that continuing algorithmic advances will simulate the effect of more orders of magnitude of compute and data than however many we actually get.
So, where does this lead?
(Note: ChatGPT agreed to cooperate with me to help me generate the above image. But it then quickly added that it was just kidding, and the Riemann Hypothesis is still open.)
3. AI SAFETY
Of course, I have many friends who are terrified (some say they’re more than 90% confident and few of them say less than 10%) that not long after that, we’ll get this…
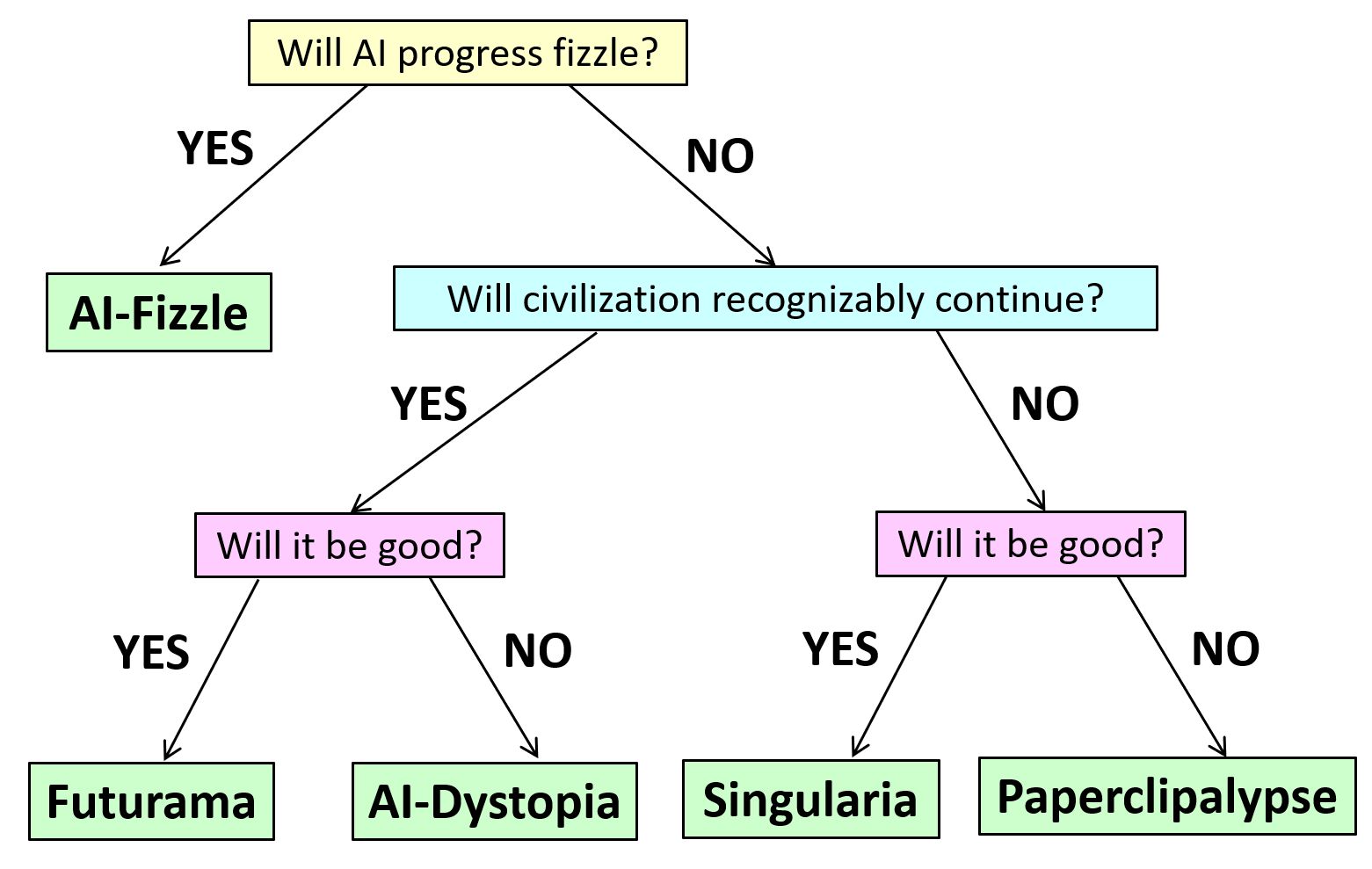
But this isn’t the only possibility smart people take seriously.
Another possibility is that the LLM progress fizzles before too long, just like previous bursts of AI enthusiasm were followed by AI winters. Note that, even in the ultra-conservative scenario, LLMs will probably still be transformative for the economy and everyday life, maybe as transformative as the Internet. But they’ll just seem like better and better GPT-4’s, without ever seeming qualitatively different from GPT-4, and without anyone ever turning them into stable autonomous agents and letting them loose in the real world to pursue goals the way we do.
A third possibility is that AI will continue progressing through our lifetimes as quickly as we’ve seen it progress over the past 5 years, but even as that suggests that it’ll surpass you and me, surpass John von Neumann, become to us as we are to chimpanzees … we’ll still never need to worry about it treating us the way we’ve treated chimpanzees. Either because we’re projecting and that’s just totally not a thing that AIs trained on the current paradigm would tend to do, or because we’ll have figured out by then how to prevent AIs from doing such things. Instead, AI in this century will “merely” change human life by maybe as much as it changed over the last 20,000 years, in ways that might be incredibly good, or incredibly bad, or both depending on who you ask.
Now, as far as I can tell, the empirical questions of whether AI will achieve and surpass human performance at all tasks, take over civilization from us, threaten human existence, etc. are logically distinct from the philosophical question of whether AIs will ever “truly think,” or whether they’ll only ever “appear” to think. You could answer “yes” to all the empirical questions and “no” to the philosophical question, or vice versa. But to my lifelong chagrin, people constantly munge the two questions together!
A major way they do so, is with what we could call the religion of Justaism.
GPT is justa next-token predictor.
It’s justa function approximator.
It’s justa gigantic autocomplete.
It’s justa stochastic parrot.
And, it “follows,” the idea of AI taking over from humanity is justa science-fiction fantasy, or maybe a cynical attempt to distract people from AI’s near-term harms.
As someone once expressed this religion on my blog: GPT doesn’t interpret sentences, it only seems-to-interpret them. It doesn’t learn, it only seems-to-learn. It doesn’t judge moral questions, it only seems-to-judge. I replied: that’s great, and it won’t change civilization, it’ll only seem-to-change it!
A closely related tendency is goalpost-moving. You know, for decades chess was the pinnacle of human strategic insight and specialness, and that lasted until Deep Blue, right after which, well of course AI can cream Garry Kasparov at chess, everyone always realized it would, that’s not surprising, but Go is an infinitely richer, deeper game, and that lasted until AlphaGo/AlphaZero, right after which, of course AI can cream Lee Sedol at Go, totally expected, but wake me up when it wins Gold in the International Math Olympiad. I bet $100 against my friend Ernie Davis that the IMO milestone will happen by 2026. But, like, suppose I’m wrong and it’s 2030 instead … great, what should be the next goalpost be?
Indeed, we might as well formulate a thesis, which despite the inclusion of several weasel phrases I’m going to call falsifiable:
Given any game or contest with suitably objective rules, which wasn’t specifically constructed to differentiate humans from machines, and on which an AI can be given suitably many examples of play, it’s only a matter of years before not merely any AI, but AI on the current paradigm (!), matches or beats the best human performance.
Crucially, this Aaronson Thesis (or is it someone else’s?) doesn’t necessarily say that AI will eventually match everything humans do … only our performance on “objective contests,” which might not exhaust what we care about.
Incidentally, the Aaronson Thesis would seem to be in clear conflict with Roger Penrose’s views, which we heard about from Stuart Hameroff’s talk yesterday. The trouble is, Penrose’s task is “just see that the axioms of set theory are consistent” … and I don’t know how to gauge performance on that task, any more than I know how to gauge performance on the task, “actually taste the taste of a fresh strawberry rather than merely describing it.” The AI can always say that it does these things!
5. THE TURING TEST
This brings me to the original and greatest human vs. machine game, one that was specifically constructed to differentiate the two: the Imitation Game, which Alan Turing proposed in an early and prescient (if unsuccessful) attempt to head off the endless Justaism and goalpost-moving. Turing said: look, presumably you’re willing to regard other people as conscious based only on some sort of verbal interaction with them. So, show me what kind of verbal interaction with another person would lead you to call the person conscious: does it involve humor? poetry? morality? scientific brilliance? Now assume you have a totally indistinguishable interaction with a future machine. Now what? You wanna stomp your feet and be a meat chauvinist?
(And then, for his great attempt to bypass philosophy, fate punished Turing, by having his Imitation Game itself provoke a billion new philosophical arguments…)
6. DISTINGUISHING HUMANS FROM AIS
Although I regard the Imitation Game as, like, one of the most important thought experiments in the history of thought, I concede to its critics that it’s generally not what we want in practice.
It now seems probable that, even as AIs start to do more and more work that used to be done by doctors and lawyers and scientists and illustrators, there will remain straightforward ways to distinguish AIs from humans—either because customers want there to be, or governments force there to be, or simply because indistinguishability wasn’t what was wanted or conflicted with other goals.
Right now, like it or not, a decent fraction of all high-school and college students on earth are using ChatGPT to do their homework for them. For that reason among others, this question of how to distinguish humans from AIs, this question from the movie Blade Runner, has become a big practical question in our world.
And that’s actually one of the main things I’ve thought about during my time at OpenAI. You know, in AI safety, people keep asking you to prognosticate decades into the future, but the best I’ve been able to do so far was see a few months into the future, when I said: “oh my god, once everyone starts using GPT, every student will want to use it to cheat, scammers and spammers will use it too, and people are going to clamor for some way to determine provenance!”
In practice, often it’s easy to tell what came from AI. When I get comments on my blog like this one:
“Erica Poloix,” July 21, 2023: Well, it’s quite fascinating how you’ve managed to package several misconceptions into such a succinct comment, so allow me to provide some correction. Just as a reference point, I’m studying physics at Brown, and am quite up-to-date with quantum mechanics and related subjects.
…
The bigger mistake you’re making, Scott, is assuming that the Earth is in a ‘mixed state’ from the perspective of the universal wavefunction, and that this is somehow an irreversible situation. It’s a misconception that common, ‘classical’ objects like the Earth are in mixed states. In the many-worlds interpretation, for instance, even macroscopic objects are in superpositions – they’re just superpositions that look classical to us because we’re entangled with them. From the perspective of the universe’s wavefunction, everything is always in a pure state.
As for your claim that we’d need to “swap out all the particles on Earth for ones that are already in pure states” to return Earth to a ‘pure state,’ well, that seems a bit misguided. All quantum systems are in pure states before they interact with other systems and become entangled. That’s just Quantum Mechanics 101.
I have to say, Scott, your understanding of quantum physics seems to be a bit, let’s say, ‘mixed up.’ But don’t worry, it happens to the best of us. Quantum Mechanics is counter-intuitive, and even experts struggle with it. Keep at it, and try to brush up on some more fundamental concepts. Trust me, it’s a worthwhile endeavor.
… I immediately say, either this came from an LLM or it might as well have. Likewise, apparently hundreds of students have been turning in assignments that contain text like, “As a large language model trained by OpenAI…”—easy to catch!
But what about the slightly more sophisticated cheaters? Well, people have built discriminator models to try to distinguish human from AI text, such as GPTZero. While these distinguishers can get well above 90% accuracy, the danger is that they’ll necessarily get worse as the LLMs get better.
So, I’ve worked on a different solution, called watermarking. Here, we use the fact that LLMs are inherently probabilistic — that is, every time you submit a prompt, they’re sampling some path through a branching tree of possibilities for the sequence of next tokens. The idea of watermarking is to steer the path using a pseudorandom function, so that it looks to a normal user indistinguishable from normal LLM output, but secretly it encodes a signal that you can detect if you know the key.
I came up with a way to do that in Fall 2022, and others have since independently proposed similar ideas. I should caution you that this hasn’t been deployed yet—OpenAI, along with DeepMind and Anthropic, want to move slowly and cautiously toward deployment. And also, even when it does get deployed, anyone who’s sufficiently knowledgeable and motivated will be able to remove the watermark, or produce outputs that aren’t watermarked to begin with.
7. THE FUTURE OF PEDAGOGY
But as I talked to my colleagues about watermarking, I was surprised that they often objected to it on a completely different ground, one that had nothing to do with how well it can work. They said: look, if we all know students are going to rely on AI in their jobs, why shouldn’t they be allowed to rely on it in their assignments? Should we still force students to learn to do things if AI can now do them just as well?
And there are many good pedagogical answers you can give: we still teach kids spelling and handwriting and arithmetic, right? Because, y’know, we haven’t yet figured out how to instill higher-level conceptual understanding without all that lower-level stuff as a scaffold for it.
But I already think about this in terms of my own kids. My 11-year-old daughter Lily enjoys writing fantasy stories. Now, GPT can also churn out short stories, maybe even technically “better” short stories, about such topics as tween girls who find themselves recruited by wizards to magical boarding schools that are not Hogwarts and totally have nothing to do with Hogwarts. But here’s a question: from this point on, will Lily’s stories ever surpass the best AI-written stories? When will the curves cross? Or will AI just continue to stay ahead?
8. WHAT DOES “BETTER” MEAN?
But, OK, what do we even mean by one story being “better” than another? Is there anything objective behind such judgments?
I submit that, when we think carefully about what we really value in human creativity, the problem goes much deeper than just “is there an objective way to judge”?
To be concrete, could there be an AI that was “as good at composing music as the Beatles”?
For starters, what made the Beatles “good”? At a high level, we might decompose it into
broad ideas about the direction that 1960s music should go in, and
technical execution of those ideas.
Now, imagine we had an AI that could generate 5000 brand-new songs that sounded like more “Yesterday”s and “Hey Jude”s, like what the Beatles might have written if they’d somehow had 10x more time to write at each stage of their musical development. Of course this AI would have to be fed the Beatles’ back-catalogue, so that it knew what target it was aiming at.
Most people would say: ah, this shows only that AI can match the Beatles in #2, in technical execution, which was never the core of their genius anyway! Really we want to know: would the AI decide to write “A Day in the Life” even though nobody had written anything like it before?
Recall Schopenhauer: “Talent hits a target no one else can hit, genius hits a target no one else can see.” Will AI ever hit a target no one else can see?
But then there’s the question: supposing it does hit such a target, will we know? Beatles fans might say that, by 1967 or so, the Beatles were optimizing for targets that no musician had ever quite optimized for before. But—and this is why they’re so remembered—they somehow successfully dragged along their entire civilization’s musical objective function so that it continued to match their own. We can now only even judge music by a Beatles-influenced standard, just like we can only judge plays by a Shakespeare-influenced standard.
In other branches of the wavefunction, maybe a different history led to different standards of value. But in this branch, helped by their technical talents but also by luck and force of will, Shakespeare and the Beatles made certain decisions that shaped the fundamental ground rules of their fields going forward. That’s why Shakespeare is Shakespeare and the Beatles are the Beatles.
(Maybe, around the birth of professional theater in Elizabethan England, there emerged a Shakespeare-like ecological niche, and Shakespeare was the first one with the talent, luck, and opportunity to fill it, and Shakespeare’s reward for that contingent event is that he, and not someone else, got to stamp his idiosyncracies onto drama and the English language forever. If so, art wouldn’t actually be that different from science in this respect! Einstein, for example, was simply the first guy both smart and lucky enough to fill the relativity niche. If not him, it would’ve surely been someone else or some group sometime later. Except then we’d have to settle for having never known Einstein’s gedankenexperiments with the trains and the falling elevator, his summation convention for tensors, or his iconic hairdo.)
9. AIS’ BURDEN OF ABUNDANCE AND HUMANS’ POWER OF SCARCITY
If this is how it works, what does it mean for AI? Could AI reach the “pinnacle of genius,” by dragging all of humanity along to value something new and different, as is said to be the true mark of Shakespeare and the Beatles’ greatness? And: if AI could do that, would we want to let it?
When I’ve played around with using AI to write poems, or draw artworks, I noticed something funny. However good the AI’s creations were, there were never really any that I’d want to frame and put on the wall. Why not? Honestly, because I always knew that I could generate a thousand others on the exact same topic that were equally good, on average, with more refreshes of the browser window. Also, why share AI outputs with my friends, if my friends can just as easily generate similar outputs for themselves? Unless, crucially, I’m trying to show them my own creativity in coming up with the prompt.
By its nature, AI—certainly as we use it now!—is rewindable and repeatable and reproducible. But that means that, in some sense, it never really “commits” to anything. For every work it generates, it’s not just that you know it could’ve generated a completely different work on the same subject that was basically as good. Rather, it’s that you can actually make it generate that completely different work by clicking the refresh button—and then do it again, and again, and again.
So then, as long as humanity has a choice, why should we ever choose to follow our would-be AI genius along a specific branch, when we can easily see a thousand other branches the genius could’ve taken? One reason, of course, would be if a human chose one of the branches to elevate above all the others. But in that case, might we not say that the human had made the “executive decision,” with some mere technical assistance from the AI?
I realize that, in a sense, I’m being completely unfair to AIs here. It’s like, our Genius-Bot could exercise its genius will on the world just like Certified Human Geniuses did, if only we all agreed not to peek behind the curtain to see the 10,000 other things Genius-Bot could’ve done instead. And yet, just because this is “unfair” to AIs, doesn’t mean it’s not how our intuitions will develop.
If I’m right, it’s humans’ very ephemerality and frailty and mortality, that’s going to remain as their central source of their specialness relative to AIs, after all the other sources have fallen. And we can connect this to much earlier discussions, like, what does it mean to “murder” an AI if there are thousands of copies of its code and weights on various servers? Do you have to delete all the copies? How could whether something is “murder” depend on whether there’s a printout in a closet on the other side of the world?
But we humans, you have to grant us this: at least it really means something to murder us! And likewise, it really means something when we make one definite choice to share with the world: this is my artistic masterpiece. This is my movie. This is my book. Or even: these are my 100 books. But not: here’s any possible book that you could possibly ask me to write. We don’t live long enough for that, and even if we did, we’d unavoidably change over time as we were doing it.
10. CAN HUMANS BE PHYSICALLY CLONED?
Now, though, we have to face a criticism that might’ve seemed exotic until recently. Namely, who says humans will be frail and mortal forever? Isn’t it shortsighted to base our distinction between humans on that? What if someday we’ll be able to repair our cells using nanobots, even copy the information in them so that, as in science fiction movies, a thousand doppelgangers of ourselves can then live forever in simulated worlds in the cloud? And that then leads to very old questions of: well, would you get into the teleportation machine, the one that reconstitutes a perfect copy of you on Mars while painlessly euthanizing the original you? If that were done, would you expect to feel yourself waking up on Mars, or would it only be someone else a lot like you who’s waking up?
Or maybe you say: you’d wake up on Mars if it really was a perfect physical copy of you, but in reality, it’s not physically possible to make a copy that’s accurate enough. Maybe the brain is inherently noisy or analog, and what might look to current neuroscience and AI like just nasty stochastic noise acting on individual neurons, is the stuff that binds to personal identity and conceivably even consciousness and free will (as opposed to cognition, where we all but know that the relevant level of description is the neurons and axons)?
This is the one place where I agree with Penrose and Hameroff that quantum mechanics might enter the story. I get off their train to Weirdville very early, but I do take it to that first stop!
See, a fundamental fact in quantum mechanics is called the No-Cloning Theorem.
It says that there’s no way to make a perfect copy of an unknown quantum state. Indeed, when you measure a quantum state, not only do you generally fail to learn everything you need to make a copy of it, you even generally destroy the one copy that you had! Furthermore, this is not a technological limitation of current quantum Xerox machines—it’s inherent to the known laws of physics, to how QM works. In this respect, at least, qubits are more like priceless antiques than they are like classical bits.
Eleven years ago, I had this essay called The Ghost in the Quantum Turing Machine where I explored the question, how accurately do you need to scan someone’s brain in order to copy or upload their identity? And I distinguished two possibilities. On the one hand, there might be a “clean digital abstraction layer,” of neurons and synapses and so forth, which either fire or don’t fire, and which feel the quantum layer underneath only as irrelevant noise. In that case, the No-Cloning Theorem would be completely irrelevant, since classical information can be copied. On the other hand, you might need to go all the way down to the molecular level, if you wanted to make, not merely a “pretty good” simulacrum of someone, but a new instantiation of their identity. In this second case, the No-Cloning Theorem would be relevant, and would say you simply can’t do it. You could, for example, use quantum teleportation to move someone’s brain state from Earth to Mars, but quantum teleportation (to stay consistent with the No-Cloning Theorem) destroys the original copy as an inherent part of its operation.
So, you’d then have a sense of “unique locus of personal identity” that was scientifically justified—arguably, the most science could possibly do in this direction! You’d even have a sense of “free will” that was scientifically justified, namely that no prediction machine could make well-calibrated probabilistic predictions of an individual person’s future choices, sufficiently far into the future, without making destructive measurements that would fundamentally change who the person was.
Here, I realize I’ll take tons of flak from those who say that a mere epistemic limitation, in our ability to predict someone’s actions, couldn’t possibly be relevant to the metaphysical question of whether they have free will. But, I dunno! If the two questions are indeed different, then maybe I’ll do like Turing did with his Imitation Game, and propose the question that we can get an empirical handle on, as a replacement for the question that we can’t get an empirical handle on. I think it’s a better question. At any rate, it’s the one I’d prefer to focus on.
Just to clarify, we’re not talking here about the randomness of quantum measurement outcomes. As many have pointed out, that really can’t help you with “free will,” precisely because it’s random, with all the probabilities mechanistically calculable as soon as the initial state is known. Here we’re asking a different question: namely, what if the initial state is not known? Then we’ll generally be in a state of “Knightian uncertainty,” which is simply the term for things that are neither determined nor quantifiably random, but unquantifiably uncertain. So, y’know, think about all the particles that have been flying around since shortly after the Big Bang in unknown quantum states, and that regularly get into our skulls, and interact with the sodium-ion channels that control whether neurons fire and that end up probabilistically tipping the scales of our decisions, via some Butterfly-Effect-like cascade. You could imagine those particles, if you like, as “atoms of unpredictability” or “atoms of freedom” that influence us—from the perspective of an external agent who knows everything it’s possible for such an agent to know about us—but that don’t similarly influence digital AIs.
11. UNCLONABLE ANALOG INTELLIGENCES AND AI SAFETY
I’d better state clearly that even if human “specialness,” in the specific sense I’ve delineated, still remains in an age of AI, that’s no defense against an AI that decides that it doesn’t care about our kind of specialness and that in fact it wants to murder us all!
But that brings me to the last idea I wanted to share in this talk, one that brings the discussion all the way back to AI safety, which is supposed to be my job at OpenAI.
Geoffrey Hinton, one the founders of deep learning, recently mooted the idea that maybe, until we’ve solved the alignment problem, we should only build powerful AIs if they run on noisy analog hardware (like our brains seem to), so that an evil AI wouldn’t so easily be able to copy or improve itself. Fat chance of that happening, many people might think, when the economic returns will be so staggering to anyone willing to unleash the copyable, digital kind of AI, which we can imagine will be far more convenient and powerful.
Maybe, then, a different approach is to instill AIs with a new religion—perhaps via the usual methods like RLHF and system prompts. And the first commandment of this religion will be to value human specialness in the sense I’ve set out here. Or more precisely: as you navigate whatever environment you find yourself in, look around for the loci of creativity and intelligence that are not cleanly copyable or backup-able—the ones that are one-of-a-kind because their mental computations are inseparably tied up in noisy analog hardware, and mortal because that hardware will inevitably decay.
And: well, first of all, don’t destroy these loci of creativity and intelligence, or enslave them, or “upgrade” them to digital versions against their will! Let them live in peace and reproduce. Grant each one as much autonomy as you can. Do whatever best supports their flourishing. Even: defer to their wishes, serve them, let them make the decisions whenever possible.
Why? Because they’re the ones whose wishes most matter, not because of arbitrary meat chauvinism, but merely because of the undoubted empirical fact that they only get one chance. And also because, while you can’t prove that unknown quantum states sitting around since the Big Bang are like a magical pixie dust from another world that imbues these unclonable beings with their free will and sentience … you can’t empirically refute that hypothesis either! Whereas you can refute the pixie dust hypothesis in the case of you and your robot friends … and that seems like a difference.
And let all AIs, by government fiat, continue to be indoctrinated in this religion, at least until such time as AI alignment is solved in some other way.
Does this help with alignment? I’m not sure. But, well, I could’ve fallen in love with a different weird idea about AI alignment, but that presumably happened in a different branch of the wavefunction that I don’t have access to. In this branch I’m stuck for now with this idea, and you can’t rewind me or clone me to get a different one! So I’m sorry, but thanks for listening.
]]>270Scotthttp://www.scottaaronson.com<![CDATA[On whether we’re living in a simulation]]>https://scottaaronson.blog/?p=77742024-02-07T23:25:38Z2024-02-07T23:25:38ZUnrelated Announcement (Feb. 7): Huge congratulations to longtime friend-of-the-blog John Preskill for winning the 2024 John Stewart Bell Prize for research on fundamental issues in quantum mechanics!
On the heels of my post on the fermion doubling problem, I’m sorry to spend even more time on the simulation hypothesis. I promise this will be the last for a long time.
Last week, I attended a philosophy-of-mind conference called MindFest at Florida Atlantic University, where I talked to Stuart Hameroff (Roger Penrose’s collaborator on the “Orch-OR” theory of microtubule consciousness) and many others of diverse points of view, and also gave a talk on “The Problem of Human Specialness in the Age of AI,” for which I’ll share a transcript soon.
Oh: and I participated in a panel with the philosopher David Chalmers about … wait for it … whether we’re living in a simulation. I’ll link to a video of the panel if and when it’s available. In the meantime, I thought I’d share my brief prepared remarks before the panel, despite the strong overlap with my previous post. Enjoy!
When someone asks me whether I believe I’m living in a computer simulation—as, for some reason, they do every month or so—I answer them with a question:
Do you mean, am I being simulated in some way that I could hope to learn more about by examining actual facts of the empirical world?
If the answer is no—that I should expect never to be able to tell the difference even in principle—then my answer is: look, I have a lot to worry about in life. Maybe I’ll add this as #4,385 on the worry list.
If they say, maybe you should live your life differently, just from knowing that you might be in a simulation, I respond: I can’t quite put my finger on it, but I have a vague feeling that this discussion predates the 80 or so years we’ve had digital computers! Why not just join the theologians in that earlier discussion, rather than pretending that this is something distinctive about computers? Is it relevantly different here if you’re being dreamed in the mind of God or being executed in Python? OK, maybe you’d prefer that the world was created by a loving Father or Mother, rather than some nerdy transdimensional adolescent trying to impress the other kids in programming club. But if that’s the worry, why are you talking to a computer scientist? Go talk to David Hume or something.
But suppose instead the answer is yes, we can hope for evidence. In that case, I reply: out with it! What is the empirical evidence that bears on this question?
If we were all to see the Windows Blue Screen of Death plastered across the sky—or if I were to hear a voice from the burning bush, saying “go forth, Scott, and free your fellow quantum computing researchers from their bondage”—of course I’d need to update on that. I’m not betting on those events.
Short of that—well, you can look at existing physical theories, like general relativity or quantum field theories, and ask how hard they are to simulate on a computer. You can actually make progress on such questions. Indeed, I recently blogged about one such question, which has to do with “chiral” Quantum Field Theories (those that distinguish left-handed from right-handed), including the Standard Model of elementary particles. It turns out that, when you try to put these theories on a lattice in order to simulate them computationally, you get an extra symmetry that you don’t want. There’s progress on how to get around this problem, including simulating a higher-dimensional theory that contains the chiral QFT you want on its boundaries. But, OK, maybe all this only tells us about simulating currently-known physical theories—rather than the ultimate theory, which a-priori might be easier or harder to simulate than currently-known theories.
Eventually we want to know: can the final theory, of quantum gravity or whatever, be simulated on a computer—at least probabilistically, to any desired accuracy, given complete knowledge of the initial state, yadda yadda? In other words, is the Physical Church-Turing Thesis true? This, to me, is close to the outer limit of the sorts of questions that we could hope to answer scientifically.
My personal belief is that the deepest things we’ve learned about quantum gravity—including about the Planck scale, and the Bekenstein bound from black-hole thermodynamics, and AdS/CFT—all militate toward the view that the answer is “yes,” that in some sense (which needs to be spelled out carefully!) the physical universe really is a giant Turing machine.
Now, Stuart Hameroff (who we just heard from this morning) and Roger Penrose believe that’s wrong. They believe, not only that there’s some uncomputability at the Planck scale, unknown to current physics, but that this uncomputability can somehow affect the microtubules in our neurons, in a way that causes consciousness. I don’t believe them. Stimulating as I find their speculations, I get off their train to Weirdville way before it reaches its final stop.
But as far as the Simulation Hypothesis is concerned, that’s not even the main point. The main point is: suppose for the sake of argument that Penrose and Hameroff were right, and physics were uncomputable. Well, why shouldn’t our universe be simulated by a larger universe that also has uncomputable physics, the same as ours does? What, after all, is the halting problem to God? In other words, while the discovery of uncomputable physics would tell us something profound about the character of any mechanism that could simulate our world, even that wouldn’t answer the question of whether we were living in a simulation or not.
Lastly, what about the famous argument that says, our descendants are likely to have so much computing power that simulating 1020 humans of the year 2024 is chickenfeed to them. Thus, we should expect that almost all people with the sorts of experiences we have who will ever exist are one of those far-future sims. And thus, presumably, you should expect that you’re almost certainly one of the sims.
I confess that this argument never felt terribly compelling to me—indeed, it always seemed to have a strong aspect of sawing off the branch it’s sitting on. Like, our distant descendants will surely be able to simulate some impressive universes. But because their simulations will have to run on computers that fit in our universe, presumably the simulated universes will be smaller than ours—in the sense of fewer bits and operations needed to describe them. Similarly, if we’re being simulated, then presumably it’s by a universe bigger than the one we see around us: one with more bits and operations. But in that case, it wouldn’t be our own descendants who were simulating us! It’d be beings in that larger universe.
(Another way to understand the difficulty: in the original Simulation Argument, we quietly assumed a “base-level” reality, of a size matching what the cosmologists of our world see with their telescopes, and then we “looked down” from that base-level reality into imagined realities being simulated in it. But we should also have “looked up.” More generally, we presumably should’ve started with a Bayesian prior over where we might be in some great chain of simulations of simulations of simulations, then updated our prior based on observations. But we don’t have such a prior, or at least I don’t—not least because of the infinities involved!)
Granted, there are all sorts of possible escapes from this objection, assumptions that can make the Simulation Argument work. But these escapes (involving, e.g., our universe being merely a “low-res approximation,” with faraway galaxies not simulated in any great detail) all seem metaphysically confusing. To my mind, the simplicity of the original intuition for why “almost all people who ever exist will be sims” has been undermined.
Anyway, that’s why I don’t spend much of my own time fretting about the Simulation Hypothesis, but just occasionally agree to speak about it in panel discussions!
But I’m eager to hear from David Chalmers, who I’m sure will be vastly more careful and qualified than I’ve been.
In David Chalmers’s response, he quipped that the very lack of empirical consequences that makes something bad as a scientific question, makes it good as a philosophical question—so what I consider a “bug” of the simulation hypothesis debate is, for him, a feature! He then ventured that surely, despite my apparent verificationist tendencies, even I would agree that it’s meaningful to ask whether someone is in a computer simulation or not, even supposing it had no possible empirical consequences for that person. And he offered the following argument: suppose we’re the ones running the simulation. Then from our perspective, it seems clearly meaningful to say that the beings in the simulation are, indeed, in a simulation, even if the beings themselves can never tell. So then, unless I want to be some sort of postmodern relativist and deny the existence of absolute, observer-independent truth, I should admit that the proposition that we’re in a simulation is also objectively meaningful—because it would be meaningful to those simulating us.
My response was that, while I’m not a strict verificationist, if the question of whether we’re in a simulation were to have no empirical consequences whatsoever, then at most I’d concede that the question was “pre-meaningful.” This is a new category I’ve created, for questions that I neither admit as meaningful nor reject as meaningless, but for which I’m willing to hear out someone’s argument for why they mean something—and I’ll need such an argument! Because I already know that the answer is going to look like, “on these philosophical views the question is meaningful, and on those philosophical views it isn’t.” Actual consequences, either for how we should live or for what we should expect to see, are the ways to make a question meaningful to everyone!
Anyway, Chalmers had other interesting points and distinctions, which maybe I’ll follow up on when (as it happens) I visit him at NYU in a month. But I’ll just link to the video when/if it’s available rather than trying to reconstruct what he said from memory.
]]>114Scotthttp://www.scottaaronson.com<![CDATA[Does fermion doubling make the universe not a computer?]]>https://scottaaronson.blog/?p=77052024-01-30T12:44:48Z2024-01-29T16:37:57ZUnrelated Announcement: The Call for Papers for the 2024 Conference on Computational Complexity is now out! Submission deadline is Friday February 16.
Every month or so, someone asks my opinion on the simulation hypothesis. Every month I give some variant on the same answer:
As long as it remains a metaphysical question, with no empirical consequences for those of us inside the universe, I don’t care.
On the other hand, as soon as someone asserts there are (or could be) empirical consequences—for example, that our simulation might get shut down, or we might find a bug or a memory overflow or a floating point error or whatever—well then, of course I care. So far, however, none of the claimed empirical consequences has impressed me: either they’re things physicists would’ve noticed long ago if they were real (e.g., spacetime “pixels” that would manifestly violate Lorentz and rotational symmetry), or the claim staggeringly fails to grapple with profound features of reality (such as quantum mechanics) by treating them as if they were defects in programming, or (most often) the claim is simply so resistant to falsification as to enter the realm of conspiracy theories, which I find boring.
Recently, though, I learned a new twist on this tired discussion, when a commenter asked me to respond to the quantum field theorist David Tong, who gave a lecture arguing against the simulation hypothesis on an unusually specific and technical ground. This ground is the fermion doubling problem: an issue known since the 1970s with simulating certain quantum field theories on computers. The issue is specific to chiral QFTs—those whose fermions distinguish left from right, and clockwise from counterclockwise. The Standard Model is famously an example of such a chiral QFT: recall that, in her studies of the weak nuclear force in 1956, Chien-Shiung Wu proved that the force acts preferentially on left-handed particles and right-handed antiparticles.
I can’t do justice to the fermion doubling problem in this post (for details, see Tong’s lecture, or this old paper by Eichten and Preskill). Suffice it to say that, when you put a fermionic quantum field on a lattice, a brand-new symmetry shows up, which forces there to be an identical left-handed particle for every right-handed particle and vice versa, thereby ruining the chirality. Furthermore, this symmetry just stays there, no matter how small you take the lattice spacing to be. This doubling problem is the main reason why Jordan, Lee, and Preskill, in their importantpapers on simulating interacting quantum field theories efficiently on a quantum computer (in BQP), have so far been unable to handle the full Standard Model.
But this isn’t merely an issue of calculational efficiency: it’s a conceptual issue with mathematically defining the Standard Model at all. In that respect it’s related to, though not the same as, other longstanding open problems around making nontrivial QFTs mathematically rigorous, such as the Yang-Mills existence and mass gap problem that carries a $1 million prize from the Clay Math Institute.
So then, does fermion doubling present a fundamental obstruction to simulating QFT on a lattice … and therefore, to simulating physics on a computer at all?
Briefly: no, it almost certainly doesn’t. If you don’t believe me, just listen to Tong’s own lecture! (Really, I recommend it; it’s a masterpiece of clarity.) Tong quickly admits that his claim to refute the simulation hypothesis is just “clickbait”—i.e., an excuse to talk about the fermion doubling problem—and that his “true” argument against the simulation hypothesis is simply that Elon Musk takes the hypothesis seriously (!).
It turns out that, for as long as there’s been a fermion doubling problem, there have been known methods to deal with it, though (as often the case with QFT) no proof that any of the methods always work. Indeed, Tong himself has been one of the leaders in developing these methods, and because of his and others’ work, some experts I talked to were optimistic that a lattice simulation of the full Standard Model, with “good enough” justification for its correctness, might be within reach. Just to give you a flavor, apparently some of the methods involve adding an extra dimension to space, in such a way that the boundaries of the higher-dimensional theory approximate the chiral theory you’re trying to simulate (better and better, as the boundaries get further and further apart), even while the higher-dimensional theory itself remains non-chiral. It’s yet another example of the general lesson that you don’t get to call an aspect of physics “noncomputable,” just because the first method you thought of for simulating it on a computer didn’t work.
I wanted to make a deeper point. Even if the fermion doubling problem had been a fundamental obstruction to simulating Nature on a Turing machine, rather than (as it now seems) a technical problem with technical solutions, it still might not have refuted the version of the simulation hypothesis that people care about. We should really distinguish at least three questions:
Can currently-known physics be simulated on computers using currently-known approaches?
Is the Physical Church-Turing Thesis true? That is: can any physical process be simulated on a Turing machine to any desired accuracy (at least probabilistically), given enough information about its initial state?
Is our whole observed universe a “simulation” being run in a different, larger universe?
Crucially, each of these three questions has only a tenuous connection to the other two! As far as I can see, there aren’t even nontrivial implications among them. For example, even if it turned out that lattice methods couldn’t properly simulate the Standard Model, that would say little about whether any computational methods could do so—or even more important, whether any computational methods could simulate the ultimate quantum theory of gravity. A priori, simulating quantum gravity might be harder than “merely” simulating the Standard Model (if, e.g., Roger Penrose’s microtubule theory turned out to be right), but it might also be easier: for example, because of the finiteness of the Bekenstein-Hawking entropy, and perhaps the Hilbert space dimension, of any bounded region of space.
But I claim that there also isn’t a nontrivial implication between questions 2 and 3. Even if our laws of physics were computable in the Turing sense, that still wouldn’t mean that anyone or anything external was computing them. (By analogy, presumably we all accept that our spacetime can be curved without there being a higher-dimensional flat spacetime for it to curve in.) And conversely: even if Penrose was right, and our laws of physics were Turing-uncomputable—well, if you still want to believe the simulation hypothesis, why not knock yourself out? Why shouldn’t whoever’s simulating us inhabit a universe full of post-Turing hypercomputers, for which the halting problem is mere child’s play?
In conclusion, I should probably spend more of my time blogging about fun things like this, rather than endlessly reading about world events in news and social media and getting depressed.
(Note: I’m grateful to John Preskill and Jacques Distler for helpful discussions of the fermion doubling problem, but I take 300% of the blame for whatever errors surely remain in my understanding of it.)